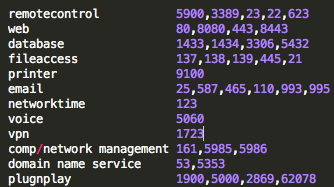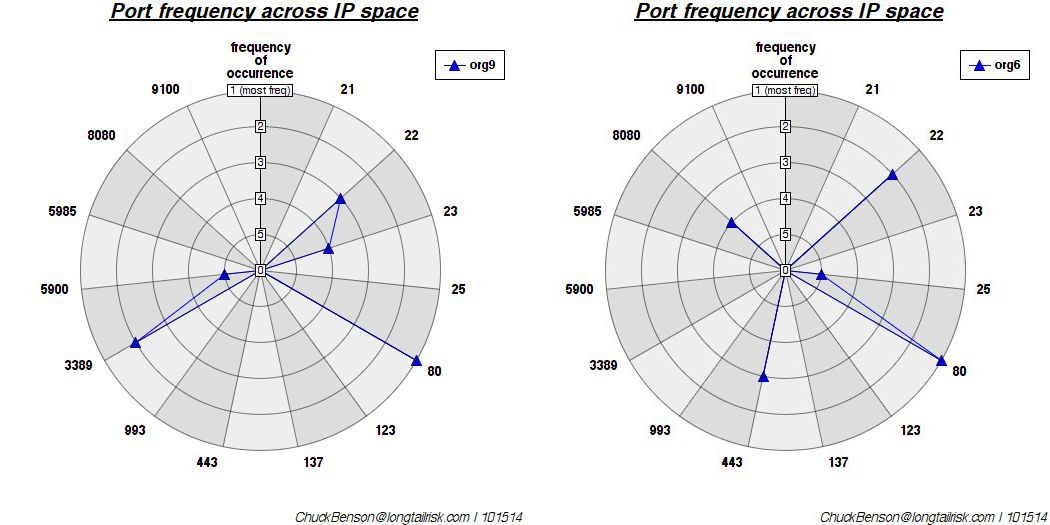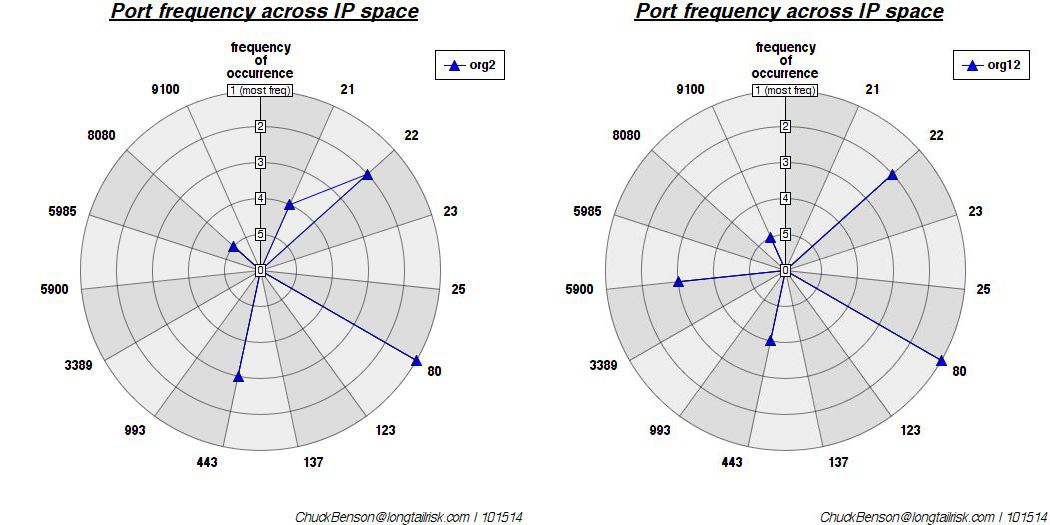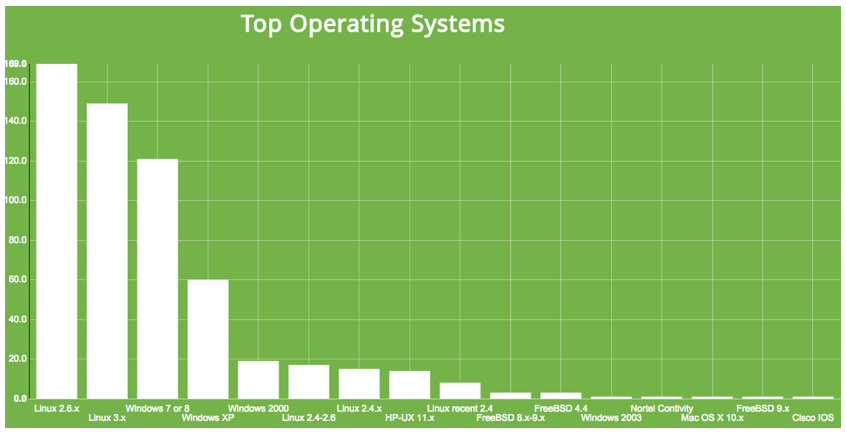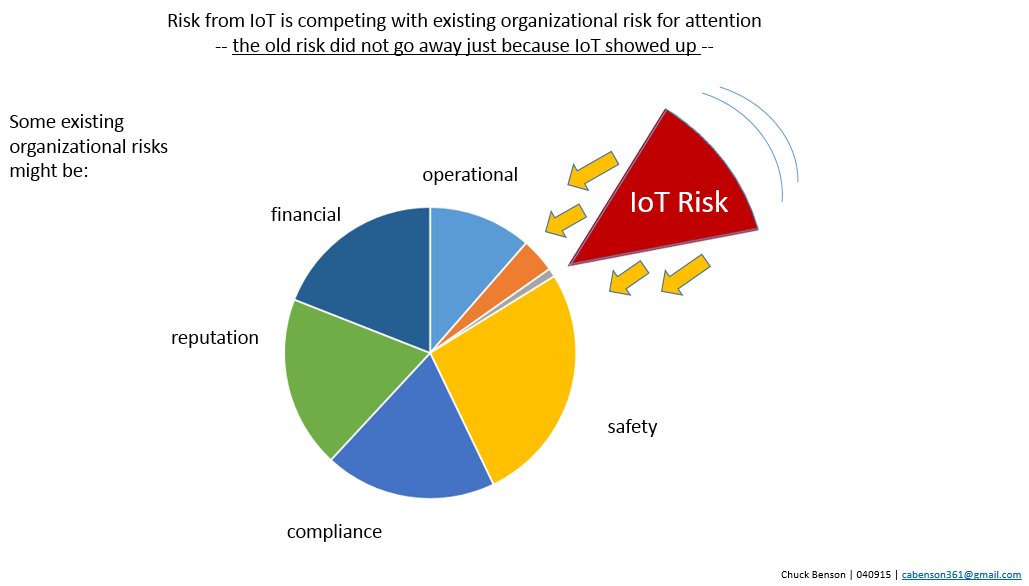
adding risk from IoT doesn’t mean the existing risk to an organization conveniently disappeared …
There is a lot of conversation regarding security, privacy, safety and other issues regarding the ongoing proliferation of the Internet of Things (IoT). While IoT promises many helpful and useful things, concern about how it might (and will) be misused are valid. However, there are more than a couple of challenges to addressing this new source of risk to an organization.
Lions and Tigers and Bears
It’s easy for anyone to call out things that could happen with the IoT growth. Medical devices can be hacked , SmartMeters can be compromised and steal privacy information, the utility grid is widening its attack surface, drone video is intercepted and hacked , and countless others . Long live fear, uncertainty, and doubt, right? While highlighting examples of IoT issues is important, the larger and more difficult thing for an organization to do is to communicate risk around IoT in a way that allows it to be managed.
Communicating IoT risk in an organization
Within an organization that already manages risk in some form, communicating and socializing the idea of IoT risk can be a challenge. There are at least two broad components to that challenge:
- IoT defies traditional classification/categorization and is still little understood. It’s hard for people to wrap their heads around it
- the other risks that the organization faces are still there. They haven’t gone away and IoT risk only adds to that
In order to begin to manage IoT risk, management must have some vocabulary for it. IoT is still new, its effects largely unknown and likely emergent, and precedents and analogies are few. We need to surface some language and concepts for it so that it can be discussed.
Another significant aspect of communicating IoT risk issues is that the other risks that an organization already faces — safety, liability, financial loss, reputation damage, technology challenges, business competition, and many more have not gone away. These risks are still there. We are asking senior management to make room in their list of existing risks that they are wrestling with to add yet more risk. And possibly substantially more risk. Nobody wants to hear this.
Because of this, how we communicate these security, privacy, and risk issues is important. We are competing for a small slice of available cognitive bandwidth, so we must use this opportunity to communicate as well as we can.
Lather, Rinse, Repeat
If you either want to or are tasked with communicating IoT risk in your organization, I would suggest starting here:
- find out what other risk the organization is already working with. Is there an annual report? Is there someone in the know in your network?
- identify places where IoT is already in your organization or where you expect it
- use the language of managing existing risk in your organization to begin to talk about IoT risk. If you have existing IoT risk examples, describe them in traditional risk language for your organization
- repeat
A key to this communication is to get some IoT risk concepts out early. Give management some language to use to reflect on IoT risk and to discuss with their peers. It’s also important not to be heavy-handed in the approach. Yes, IoT risk is important, the impacts potentially very high, and the opportunities for abuse many, but the other existing risks that an organization faces haven’t gone away and they still must be managed too.