
What are our opportunities for guiding the rapidly evolving IoT ecosystem? The Internet of Things, with its explosive growth, unprecedented variety of device & system types, lack of broadly shared language and conceptual frameworks to discuss and plan, lack of precedence for implementation, and the organizationally complex consumer systems — i.e. cities and institutions — required to implement and manage these IoT systems — all make for a challenging space. It can be difficult to even know where to start. One way to add structure and framework to the conversation is to introduce some constraints — and good news! There are constraints already there! They’re just not broadly seen or talked about yet.
What does a successful IoT system implementation look like ?
A natural source for constraints is from those things that define a successful IoT System implementation in an institution or city. I use two primary components to define IoT System implementation success:
- Return on Investment (ROI)
- Cyber risk profile
Regarding the first — ROI, does the system do what we thought it would do at the costs/investment that we thought would be incurred? As discussed in a recent post on IoT System costing, determining costs of IoT Systems implementation is different from traditional enterprise systems. Most institutions and cities have little experience at it and are generally not very good at it. Further, other subtleties such as expectations of the data created from deployed IoT systems across a spectrum of populations, demographics, & constituencies directly impact perceptions of system (and investment) success.
Regarding the second — cyber risk profile, did the IoT System implementation make things worse for the institution or city? Cyber risk profile degradation can come from poorly configured devices/endpoints, insufficient management resources (skill, capacity) for endpoints and data aggregators/controllers, inadequate vendor management, and others.
Constraints drive opportunities in the IoT ecosystem
These same two analysis requirements of a city’s or institution’s success, aka constraints, can also be used by innovators and providers of IoT systems. Knowledge of these constraints by IoT systems providers, these requirements for city/institution implementation success, creates opportunity for the IoT systems innovator and provider by identifying where they can help address organizational complexities in the course of pursuing ROI and cyber risk posture/profile objectives.
IoT systems are different
As discussed in other articles and posts, IoT Systems are different. The process of selecting, procuring, implementing, & managing IoT systems is different from doing the same for traditional enterprise systems such as email, calendaring, resource and customer management, etc. At least six aspects of IoT Systems contribute to this difference:
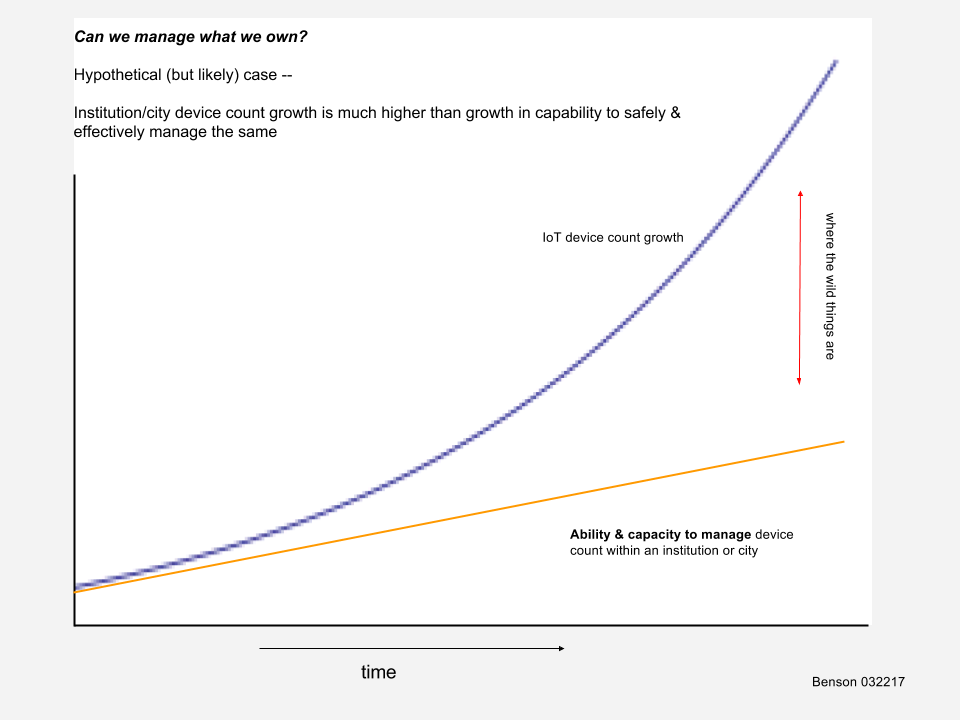
- High number and growth rate of IoT devices
- High degree of variability of device types & variability of multiple hardware/software components within a device
- Lack of language and frameworks to discuss IoT opportunities, risks
- IoT Systems span multiple organizations within an institution or city
- IoT endpoint/devices tend to be out of sight out of mind
- Lack of precedent for successfully implementing these systems, few examples, few patterns to follow
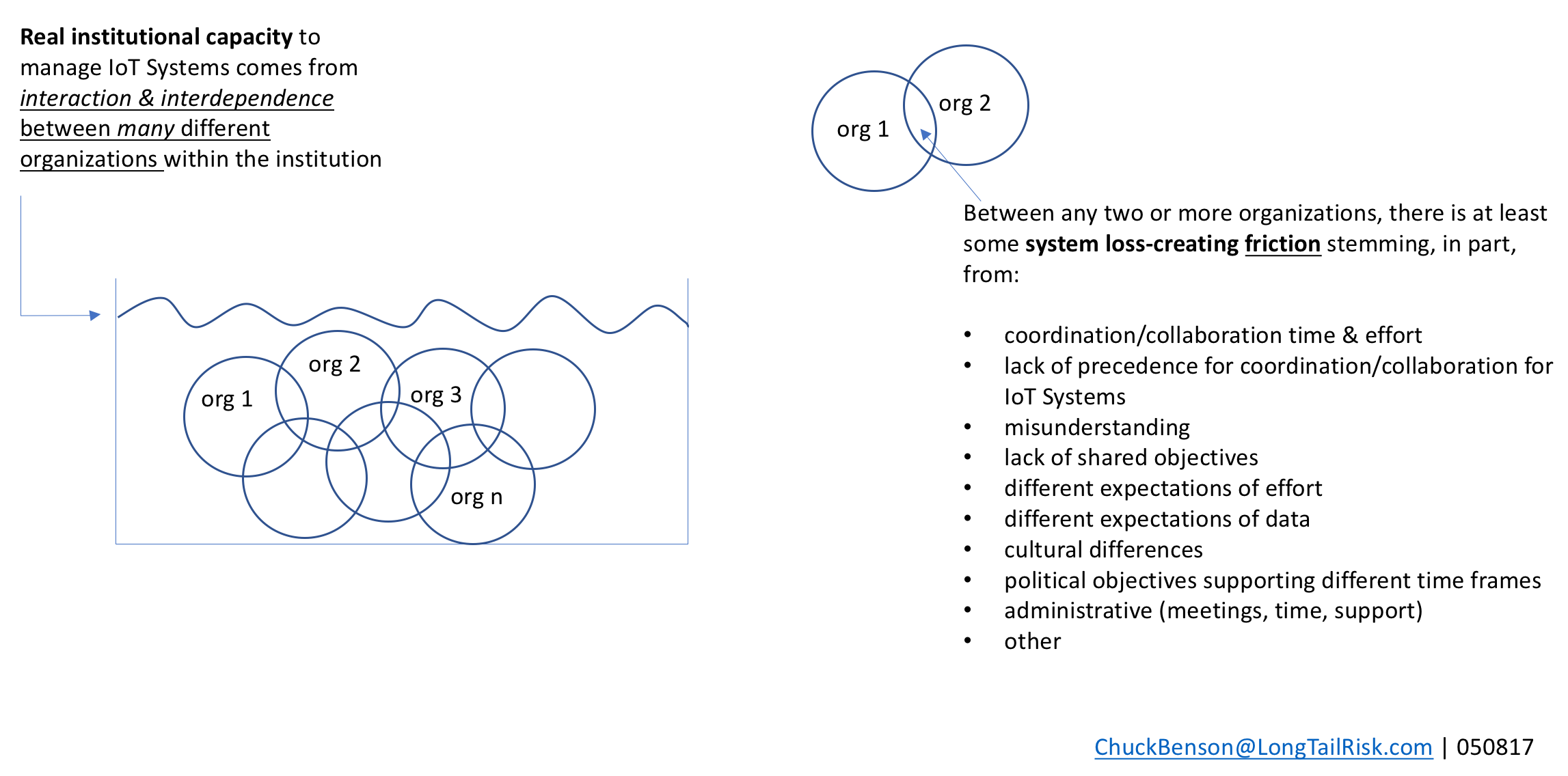
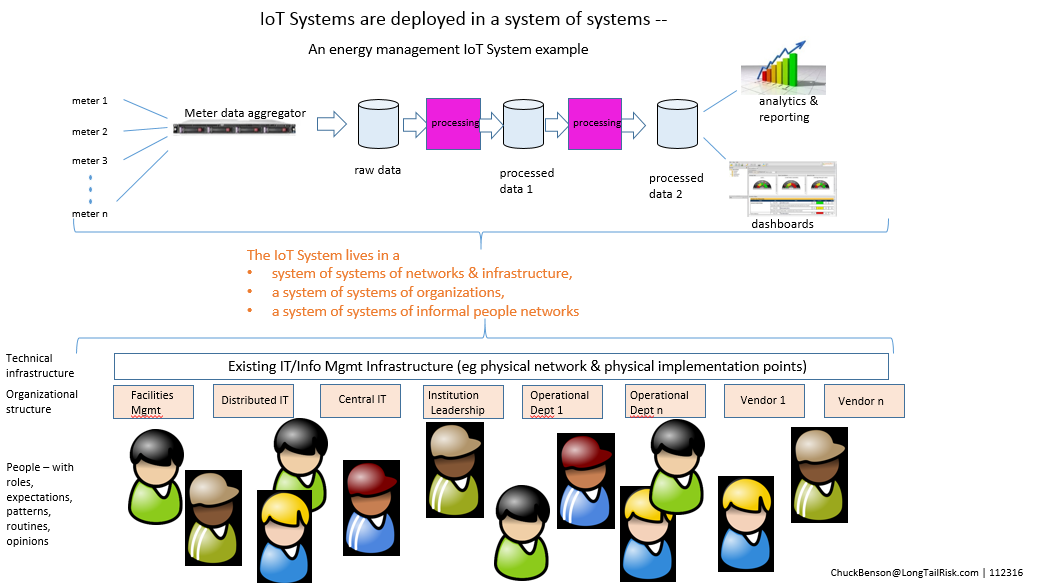
Of these differences, #4 – the organizational spanning aspect of IoT Systems — presents a subtle but substantial challenge. Deploying IoT Systems in a city or institution is not like deploying an enterprise application in a data center or SaaS in the cloud and then providing for end-user training and support. This, of course, does not mean that deploying large enterprise systems is easy by any stretch, but rather that there are more and different organizations required in the technical, operational, and management aspects of the system. Because of this, new levels of inter-organizational cooperation and collaboration are sought. And, as we all have experienced, collaboration and cooperation is frequently touted but successful collaboration and cooperation is often not achieved — “the discrepancy between the promise of collaboration and the reality of persistent failure” (Koschmann).
Cities and institutions are complex multi-component organizations that offer a complex substrate for IoT System implementation. These complex IoT product and service consuming organizations are not blank slate, clean whiteboard, or powerpoint deck solution organizations. There is little homogeneity here.
IoT Systems innovators and providers that recognize these constraints brought on by these complex consumer systems, that seek to learn the institutional organizational challenges in detail, and get in the dirt at the outset with the city or institution will ultimately be IoT Systems ecosystem drivers.
“I built it in my garage, it works there, it’ll be awesome in your city!”
Because of the seemingly unbounded potential of IoT Systems solutions, there’s also room for undifferentiated, poorly provisioned, and poorly serviced garbage in this space.
Because of the newness of IoT Systems, often there are many technologies and many vendors without particularly long track records. There are some big names in the game of course — Cisco, Microsoft, Intel, Siemens for example. But there are many providers in that long tail, both proven and unproven, and some of them will offer great innovation and value. Some of them will not. The challenge for institutions and cities is to work to separate the wheat from the chaff as they select, procure, implement, and manage IoT Systems.
Going by name brand alone is not sufficient because there will be many new innovators and providers that do indeed offer promising and solid solutions that give a reasonable likelihood of ROI and an approach that does not degrade the existing cyber risk profile of the institution. Further, sometimes large companies can be problematic because they are used to throwing their weight around, possibly invested heavily in particular approaches, and may not be open to new or alternative approaches. This may or may not be with whom a city or institution wants to work.
Eyes off the bling for a moment
So how can a city or institution begin to separate the wheat from the chaff in choosing IoT systems? An initial step can be to take one’s eyes off of the ‘bling’ for a moment. The bling is all of the feature sets and bells and whistles that most think of when they think of IoT systems. So, a three step process would be:
- Take eyes off of the bling (feature sets, bells & whistles) for a moment
- Review implementation challenges internal to the institution
- organizational spanning complexity
- calculating IoT system support costs across all organizations
- analyzing internally available skill sets and capacity
- consider what criteria different demographics will use to assess success or failure
- particularly expectations of data produced by the system
- seek input in estimating cyber risk to which an institution or city is already exposed to provide an estimated baseline
- Seek and prioritize IoT Systems innovators/providers that help address some of these internal organizational challenges and shortcomings
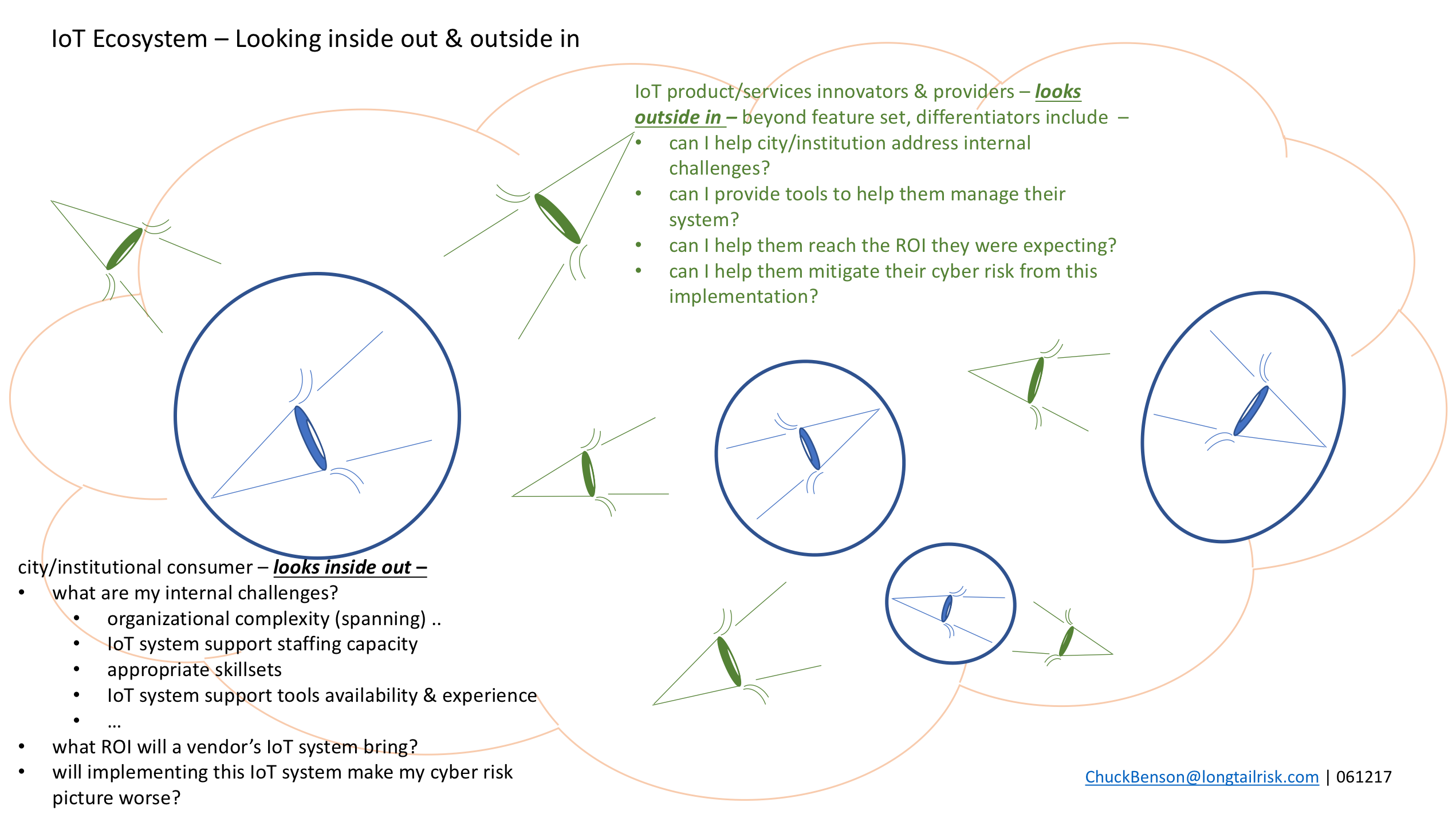
Cities and institutions look inside out — Some of their internal challenges include:
- organizational complexity (spanning)
- IoT system support staffing capacity
- appropriate skill sets
- IoT system support tools availability & experience
- what ROI will a particular provider’s IoT system bring?
- will implementing this IoT system make my cyber risk picture worse? how do I know?
IoT innovators & providers can look outside in — and use these constraints to create market differentiators for their organizations, such as:
- can I help city/institution address internal challenges?
- can I provide tools to help them manage their system?
- can I help them reach the ROI they were expecting?
- can I help them mitigate their cyber risk from this implementation?
Not just one IoT System
We’ve been talking about just one prototypical IoT System for an institution or city. In practice, institutions and cities will have many IoT Systems. Many of these IoT Systems will:
- use shared technical resources of the city or institution, eg network and supporting systems
- have interdependency with other systems
- at device level
- at data level
- to include co-existing with legacy systems & new systems
- dip into the same limited pool of skill sets and capacity for systems support
This further deepens the IoT Systems management challenge within the city or institution. Implementation challenges for these complex city and institutional consumers will only continue to grow. They won’t diminish.
IoT Systems innovators and providers that recognize and speak to this additional level of complexity — this ecosystem with multiple providers and vendors within an institution — and provide options, services, and support to help cities and institutions manage this complexity will set themselves apart from the competition and develop longer lasting relationships.
In this seemingly open-ended space of IoT systems possibilities, identifying and developing solutions for organic complex consumer constraints and challenges can be a differentiator for IoT product innovators and service providers.








 The mission of the Internet 2 Chief Innovation Office, led by
The mission of the Internet 2 Chief Innovation Office, led by  Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems
Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems