

Gaps between institutional organizations implementing & supporting IoT Systems create challenges
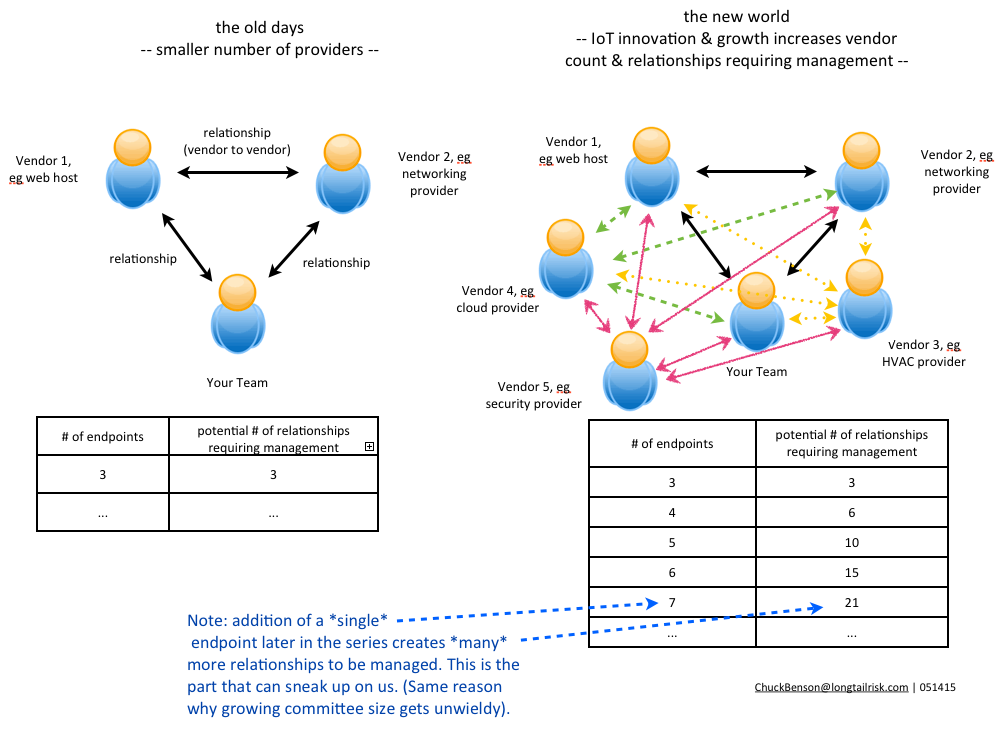
One of the unique characteristics of IoT Systems, and one that adds to the complexity of a system’s deployment, is that they tend to span many organizations and entities within the institution. This is particularly true in Higher Education institutions with their city-like aspects, multiple service lines, and wide variety of activities in their buildings and spaces. While traditional enterprise systems, such as e-mail or calendaring, are likely to be owned and operated by one or two institutional organizations, IoT Systems involve many and are deployed in the ‘complex and material manifestations’ that characterize buildings and spaces.
A Higher Education institution example might be a research lab that incorporates an automation and environmental control system that involves the facilities organization, the central IT organization, maybe a local/distributed IT organization, the lead researcher (aka Principal Investigator or PI), her lab team, at least one vendor/contractor and probably several other vendors. Between each of these, a gap forms where system ownership and accountability can fall. Everyone sees their piece, but not much of the others. There’s no one monitoring the greater Gestalt of the IoT System. And that’s where the wild things are.
Traditional enterprise systems tend to fall within the domain of central IT with use of the system being distributed around the institution. So with traditional enterprise systems, use is distributed but ownership and operation is largely with one organization. IoT Systems, on the other hand, tend to have multiple parties/organizations involved in the implementation and management, but the ownership is unclear.
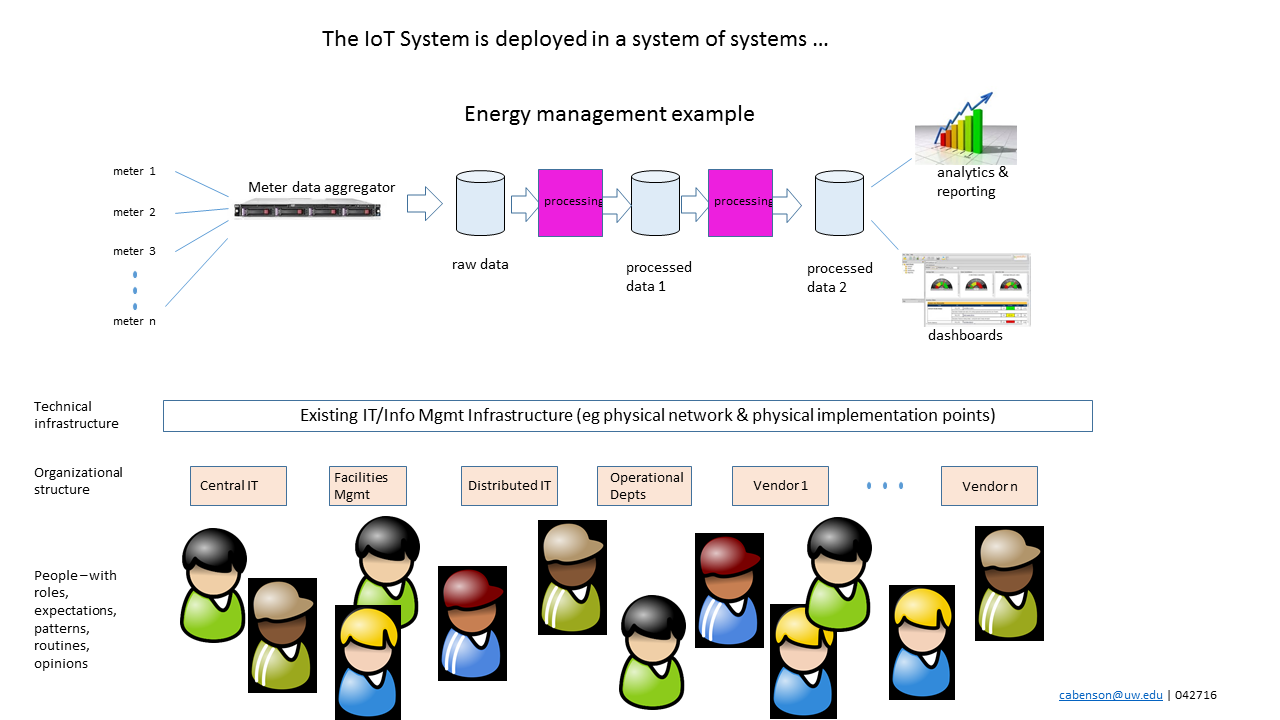
IoT Systems are systems within systems within systems …
This lack of ownership can lead to unfortunate assumptions. For example, the end user/researcher in the Higher Ed case is probably thinking, “central IT and the Chief Information Security Officer are ensuring my system is safe and secure.” The central IT group is thinking, “I’ve got no idea what they’re plugging into the network down there … I didn’t even know they bought a new system. Where did that come from? “ The facilities people might be thinking, “Okay I’ll install these 100 sensors and 50 actuators around this building and these two computers in the closet that the vendor said I had to install. The research people and central IT people will make sure it’s all configured properly.” No one is seeing the whole picture or managing the whole system to desired outcomes.
This implementation and management of IoT Systems is a part of what is being explored within Internet2’s IoT Systems Risk Management Task Force in support of Internet2’s Smart Campus Initiative.
Technology adoption in other aspects of the building industry
Research has been done in other areas of technology implementation in the building, space, and campus realms that might help shed some light on the multi-organizational challenge that IoT system implementations can bring to institutions.
Research in the Building Information Modeling (BIM) field suggests that buildings have a ‘complex social and material manifestation … [that requires] a shared frame of reference to create.’ Building Information Modeling seeks to codify or digitize the physical aspects of a space or place such that its attributes can be stored, transmitted, exchanged in a way that supports decision-making and analysis.
In their paper, “Organizational Divisions in BIM-Enabled Commercial Construction”, researchers Carrie Dossick and Gina Neff identify competing obligations within supporting/contributing organizations that limit technology adoption. They point out that BIM-enabled projects are “often tightly coupled technologically, but divided organizationally.” I believe that their observations regarding BIM projects also share common aspects of deploying and managing IoT Systems.
The Dossick/Neff research suggests that mechanical, electrical, plumbing, and fire life safety systems can be as much as 40% of the commercial construction project scope.It is likely that this number will only increase as our buildings and spaces become more alive, aware, and aggregating of information of what goes on in and around these spaces.
For the BIM implementations studied, the research suggests that there are three obligations of the people and groups contributing to the effort and that these can be in conflict with each other. The obligations are: scope, project, and company.
As I interpret the paper, scope obligation is what a person or group is supposed to accomplish for the effort – what are they tasked to do. That mission is not overarching organization and coordination of the project, but rather specific, often local, tasks that must be done in support of the effort. In the course of that work, participants in the work are naturally “advocating for their particular system.“
Projects bring together temporary teams for a particular purpose. These time boundaries and purpose boundaries create the environment for the project obligation. Specific timelines and milestones can drive the project obligation. This area can be particularly challenging as it can involve negotiations among different providers, the interests of owners, and design requirements.
Finally, obligations to company “emphasize the financial, legal, and logistical requirements” where ownership and management provide the environment and context in which work is done. This also makes sense intuitively as company is whence one’s paycheck comes. Performance today can influence today’s paycheck as well as paychecks down the road.
While not exactly the same, I think there are some parallels with IoT Systems implementation and management.
BIM implementation/adoption -> IoT Systems implementation & management
- scope -> scope
- project -> project
- company -> department/organization
To me, organizational aspects of scope and project are very similar between IoT Systems implementation/management and those observed and analyzed by the research in BIM implementation.
For IoT Systems implementation and management within an institution, internal departments and internal organizations can closely parallel that of the company that the research addresses. A person’s or group’s directives, performance expectations, and paycheck approval ultimately comes from that department or organization so there will be natural alignment there.
Leadership ‘glue’ has its limits
Finally, the paper also points out the role of leadership in an effort where there is new technology to potentially be adopted or leveraged. While strong leadership is clearly desirable, the research suggests that even good leaders often cannot overcome structural organizational problems with great efficiency or effectiveness. The authors also note that research does not yet understand what “organizational resources to be in place for effective collaboration to occur after new technologies are introduced.”
IoT System ownership for implementation & management
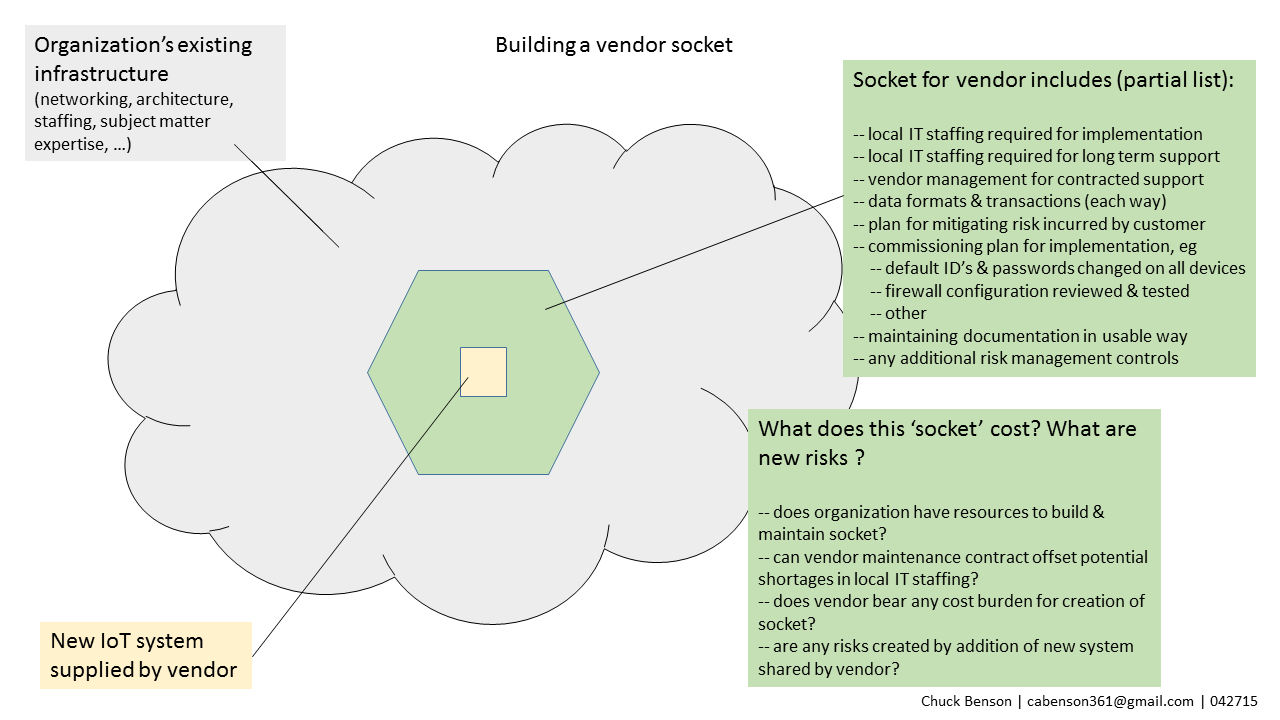
Like BIM and related technology adoption, I believe successful IoT Systems implementations have similar institutional organizational challenges. IoT Systems implementations are themselves a part of larger system of institution, organizations, and people. IoT System implementation and management success will, I believe, also require learning to work with these multiple organizations that have inherent competing obligations. While there may be other approaches to evolve to solve these organizational challenges, a reasonable place to start in the near term might be to establish organizational-spanning system ownership and accountability.
 The mission of the Internet 2 Chief Innovation Office, led by
The mission of the Internet 2 Chief Innovation Office, led by  Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems
Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems










{kind=link}