Coming apart at the seams
One of the greatest areas of risk related to the Internet of Things (IoT) in an organization, corporation, or institution comes not necessarily from the IoT systems themselves, but rather the implementation of the IoT systems. A seam forms between the delivery of the system by the vendor/provider and the use of that system by the customer. Seams, in themselves, are not bad. In fact, they’re essential for complex systems. They connect and integrate different parts of a system to work towards a cohesive whole. However, how we choose to approach and manage these seams makes a difference.
Managing the seam
Seams are where interesting things happen. College baseball changed its ball seams this year to flat instead of raised to drive more hits and home runs and, sure enough, balls are traveling an average of 20 feet further. There are seam routes in football where the receiver tries to exploit the gap between defenders. And anyone that’s ever sat in the window seat by the wing of an airplane can attest that there are many more seams than they would probably care to see. Finally, of course, seams can also be where things come apart.

More seams than we would probably care to acknowledge
Vendor relationships and vendor management have always been important for firms and institutions. However, the invasive nature of IoT systems makes vendor management particularly important to successful IoT system implementation and subsequent operation. However, the work and staffing required to manage those customer-vendor relationships and to provide the oversight needed to operate safe and effective systems often gets obfuscated by the promises and shininess of the new technology.
IoT systems are different from traditional deployments of workstations, laptops, and servers. By their very nature, IoT systems have the ability to sense, record, transmit, and/or interact with the environments in which we live and work. Further complicating the IoT systems deployments and support, these systems may well be invisible to us and organizational IT might not even know the systems exist much less be able to provide central IT support.
Firms and institutions purchase IoT devices and systems en masse to address some need in their operation. These IoT systems might be related to environmental control and energy efficiency, safety of staff and the public (fire, security, other), biometric authentication systems, surveillance systems and others. Because of this, IoT devices can be brought into an organization’s physical and cyber space by the hundreds or thousands or more. When such systems and devices are partially or improperly configured, there can be significant consequences to the organization. Similarly, a lack of planning of long-term support, whether local or via maintenance contract with the vendor or both, can also have significant implications.
Cost of building a socket
In most organizations, implementing a third-party solution, whether hardware, software, SaaS, or hybrid, requires a supporting infrastructure for that solution. I call this supporting structure a socket. The customer organization must create a socket that allows the new vendor solution to interface with appropriate parts of the customer’s existing infrastructure. Taking the time and resources to plan, build, and maintain this socket is integral to the operational success of the new system. It also provides the opportunity to manage some of the risk that the new system introduces to the organization.
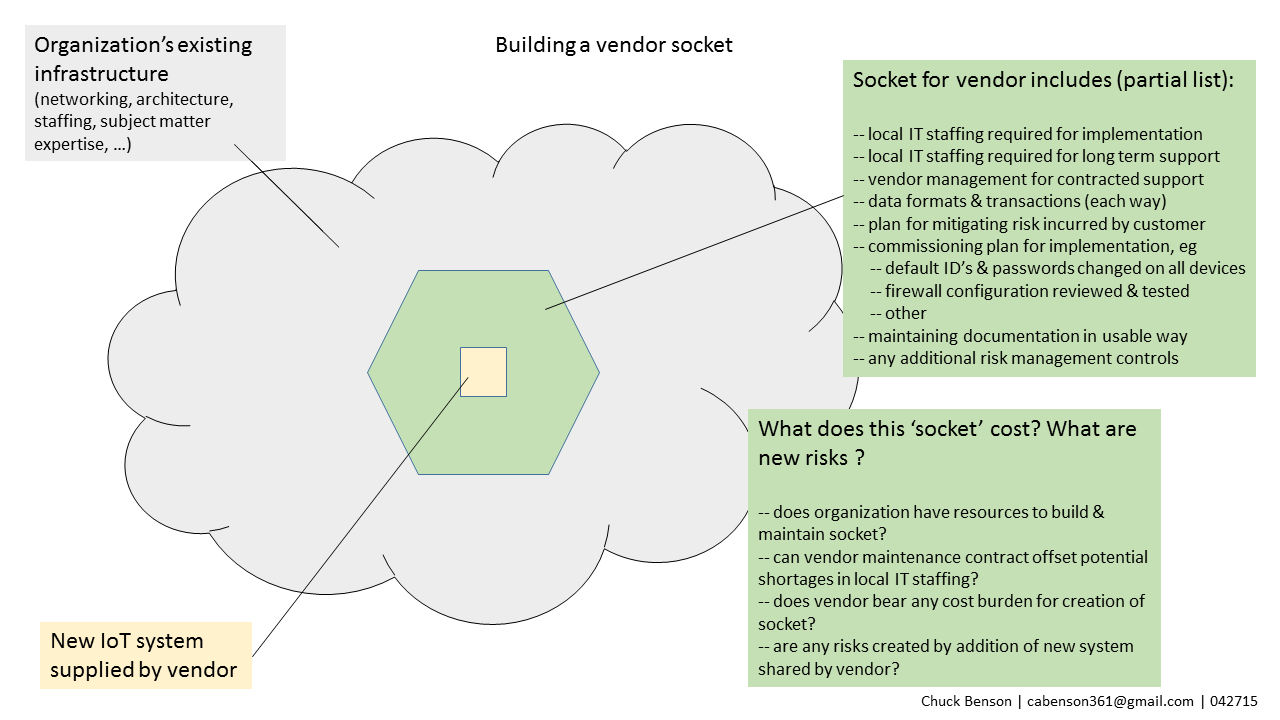
Building a socket to support vendor IoT systems
Know yourself
One of the worst case scenarios for an organization is believing that an IoT system is managed when it is actually not managed. At this point in the evolution of IoT deployments, I suspect that this scenario is more of the rule than the exception. Given the scale and speed of IoT innovation and growth and the lack of precedence for managing this sort of risk, the famed Sun Tzu guidance to know yourself can be elusive. The IoT phenomena will change how we seek to know and characterize our organizations as a part of the risk management process. A good place to start knowing ourselves is planning, building, and managing that seam where the interesting things happen.