Schneier on security illusion
Leave a reply

We have a love-hate relationship with risk and uncertainty. We hate uncertainty when it interferes with us trying to get things done such as projects we are trying to complete, programs we are developing, or things that break. We love it because of the excitement that it brings when we go to Las Vegas, or a enjoy a ball game, or watch a suspenseful movie. There’s uncertainty and risk in all of these, but that is what makes it fun and attracts us to them.
When we think of risk and uncertainty in terms of our IT and Information Management projects, programs, and objectives, and the possibility of unpleasant surprises, we are less enamored with uncertainty.
Why do we have a hard time managing uncertainty and incorporating risk-based analysis into our day-to-day work? We’ve already talked some about resource constraints that can make information risk management challenging, particularly for small and medium-sized businesses. However, there is a deeper issue that stems from over 300 years of human thought. In a nutshell, we just don’t think that way. Why is this? Who got this ball rolling? Isaac Newton.

In 1687 Isaac Newton lowers uncertainty and increases predictability with the publication of Principia
Isaac Newton (1642 – 1727) published Principia in 1687. In this treatise, Newton’s three laws of motion were presented as well as the law of universal gravity. This was a huge step forward in human knowledge and capability. Application of these laws provided unprecedented predictive power. The laws separated physics and philosophy into separate professions and formed the basis of modern engineering. Without the predictive power provided by Principia (say that three times real fast), the industrial and information revolutions would not have occurred.
Now, for the sneaky part. The increased ability to predict motion and other physical phenomena was so dramatic and the rate of knowledge change was so rapid that the seeds were planted that we must be able to predict anything. Further, the universe must be deterministic because we need only to apply Newton’s powerful laws and we can always figure out where we’re going to be. Some refer to this uber-ordered, mechanical view as Newton’s Clock.
A little over a century later, Pierre-Simon Laplace (1749-1827) takes this a step further.

Pierre-Simon Laplace ups the ante in 1814 and says that we can predict anything if we know where we started
In his publication, A Philosophical Essay on Probabilities (1814), he states:
We may regard the present state of the universe as the effect of its past and the cause of its future. An intellect which at a certain moment would know all forces that set nature in motion, and all positions of all items of which nature is composed, if this intellect were also vast enough to submit these data to analysis, it would embrace in a single formula the movements of the greatest bodies of the universe and those of the tiniest atom; for such an intellect nothing would be uncertain and the future just like the past would be present before its eyes.
In other words, Laplace is saying:
Now, almost 200 years later, we’ve got enough experience to know that things don’t always work out as planned. That is, as much as one may desire certainty, you can’t always get what you want.

!n 1969 Jagger-Richards revisit uncertainty & remind us that we can’t always get what we want
The problem is that we largely still think the Newtonian/Laplacian way.
Even after the practical and theoretical developments of the last century, eg Heisenberg’s Uncertainty Principle, the unknowability in Schrödinger’s Wave Equation and Godel’s Incompleteness, we still think the old school way on a day-to-day basis.
This gets reaffirmed in our historical IT service experience as well. We are used to systems having strong dependencies. For example, to set up a traditional content management system, there had to be supporting hardware, there had to be a functional OS on top of that, there had to be a functional database, and there had to be a current CMS framework with supporting languages. This is a very linear, dependent approach and configuration. And it was appropriate for simpler systems of the past.
The issue now is that our systems are so complex, with ultimately indeterminate interconnectivity, and systems are changing so rapidly that we can’t manage them with hard dependency mapping. Yet our basic instinct is to keep trying to do so. This is where we wrestle with risk management. It is not natural for us. Newton and Laplace still have a big hold on our thinking.
Our goal is to train ourselves to think in terms of risk, of uncertainty. One way to do this is to force ourselves to regularly apply risk management techniques such as management of a Risk Register. Here we write down things that could happen — possibilities — and also estimate how likely we think they are to occur and estimate their impact to us. When we add to and regularly review this list, we begin to get familiar with thinking and planning in terms of uncertainty.
We have to allow for and plan for uncertainty. We need to create bounds for our systems as opposed to attempting explicit system control. The days of deterministic control, or perceived control, are past. Our path forward, of managing the complexity before us, is to learn to accept and manage uncertainty.
How do you think about uncertainty in your planning? Do you have examples of dependency management that you can no longer keep up with?
There is an apocryphal anecdote that a frog can be boiled to death if it is placed in a pan with room temperature water and then slowly heating the water to boiling. The idea is that the frog continues to acclimate to the new temperature which is only slightly warmer than the previous temperature (if the temp went up in incremental chunks) and so it is never in distress and never tries to jump out. A less PETA-evoking metaphor is that of a ‘shifting baseline’ which was originally used to describe a problem in measuring rates of decline in fish populations. The idea here is that skewed research results stemmed from choosing a starting point that did not reflect changes in fish populations that had already occurred which resulted in an order of magnitude of change that was not accounted for.
We can also see this sort of effect in risk management activities where risks that were initially identified with a particular impact and likelihood (and acceptability) seem to slide to a new place over time on the risk heat map. This can be a problem because often the impact and the probability did not change and there’s no logical reason for the level of risk acceptability to have changed. I believe this slide can happen for a number of reasons:

Challenger plume after explosion
In 1986, the Space Shuttle Challenger exploded 71 seconds after liftoff. The Rogers Commission, established to investigate the mishap, created a report and panel debrief to include the testimony by the iconic Richard Feynman. Chapter 6 of the report, entitled “An Accident Rooted in History” opens with, “The Space Shuttle’s Solid Rocket Booster problem began with the faulty design of its joint and increased as both NASA and contractor management first failed to recognize it as a problem, then failed to fix it and finally treated it as an acceptable flight risk.” (italics added) Let’s recap that:
When further testing confirmed O Ring issues, instead of fixing the problem, “the reaction by both NASA and Thiokol (the contractor) was to increase the amount of damage considered ‘acceptable’.” That is, in effect, they changed criteria for risk. Implicitly, and by extension, loss of life and vehicle was now more acceptable.
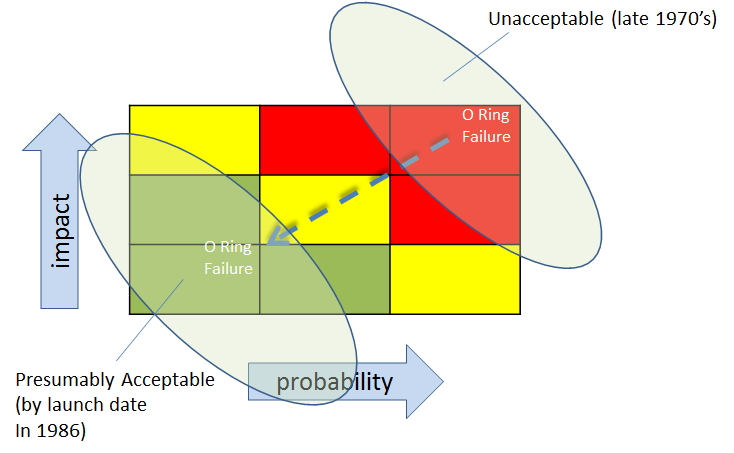
For risk to become acceptable, the criteria for impact and/or probability would have had to change — even if implicitly
Physicist Richard Feynman, on the Commission, observed:
“a kind of Russian roulette. … (The Shuttle) flies (with O-ring
erosion) and nothing happens. Then it is suggested, therefore, that
the risk is no longer so high for the next flights. We can lower our
standards a little bit because we got away with it last time. … You
got away with it, but it shouldn’t be done over and over again like
that.”
This is the sort of frog boiling or baseline shifting that we talked about earlier. Though there were many contributing factors, I believe that one of them was that they simply got familiar with and comfortable with the risk. In a way, the risk was ‘old news’.
This kind of frog boiling or baseline shifting can happen with Information Risk Management as well. As we become inundated with tasks, complexity, and knowledge of new threats and vulnerabilities, it can be tempting to reduce the importance of risk issues that were established earlier. That is, we can have a tendency to put a higher priority on the issue(s) that we have been most recently dealing with. If we are not careful, the perceptions of earlier risks can actually change. Gregory Berns discusses perception change in his book, Iconoclast.
It’s one thing to consciously re-evaluate our tolerance for difference types of risk because we have new information and new things to consider, but it is another to let our tolerance for risk slide because of fatigue, ‘information overload’, political pressure, or distraction.
More than once I’ve picked up an older Information Risk Register & Heat Map and reminded myself that there were unmitigated risks that were still there. Yes, since that time, I had new risks to deal with, but that didn’t mean that the original ones went away.
One way to help us address this non-overt perception change is to use our earlier Risk Registers and Heat Maps.
It may well be that with new knowledge of threats, vulnerabilities, and capabilities, that we have to revisit and adjust (usually increase) our tolerance for risk given our limited resources. That is fine and appropriate. However, this needs to be a conscious effort. Changing the importance of a risk issue, whether it be its impact or probability, because we are tired, overwhelmed, or because the issue is ‘old news’ doesn’t help us. We need to be methodical and consistent with our approach. Otherwise, we are just fooling ourselves.
Have you had to change your risk tolerance in your organization? Have you had to change your criteria for impact and probability? What were driving factors for re-assessing how you measure risk impact?
In describing the Alien threat that they (Ripley and the tactical team) are facing as the evening wears on, the young female protagonist, Newt, states:
“They mostly come out at night. Mostly.”
When Ripley tries to assuage her by sharing that there are armed soldiers to protect her, Newt states:
“It won’t make any difference”

Newt and Ripley
Analysis:
Let’s define this particular Risk Register item “Alien attack at night”
We have it from a first-hand observer of multiple instances of Alien attack, Newt, that they mostly come out at night. (Mostly). If we’re using Low, Medium, & High to represent probabilities 0 < p < 33%, 33% < p < 67%, 67% < p < 100%, respectively, then I think we can safely convert these observations to High likelihood of Alien attack at night.
We have direct observations of destruction and further interviewing of a first hand observer who shares that having several well-armed soldiers in place “won’t make any difference”. Given this information and defining Impact as Low = no fatalities/minor injuries, Medium = 1 to 3 fatalities (or capture with subsequent implantation & cocooning) & severe injuries , and High = greater than 3 fatalities (or capture w/subsequent implantation & cocooning) & very severe injuries (that includes Alien acid-blood burns), I believe that we can call this a High Impact.
If Hudson were keeping his Risk Register current, I think he could reasonably update with:
How would you assess this situation?
One of the most challenging aspects of work for an IT or information management professional is to communicate risk. If you are in a resource-constrained business, e.g. small and medium size businesses (SMB), that hasn’t analyzed information risk before, consider communicating it the first time in a single page.
The reason for a single page communication is that risk can be so complicated and obscure and IT technologies, concepts, and vocabulary can also be complicated and obscure that the combination of both can go well beyond mystifying to an audience not familiar with either or both (which is most people).
A few years ago I was in a position to try to communicate information risk to a number of highly educated, highly accomplished, and high performing professionals with strong opinions (doctors). I only had a tiny sliver of time and attention for them to listen to my pitch on the information risk in their work environment. If I tried some sort of multi-page analysis and long presentation, I would have been able to hear the ‘clunk’ as their eyes rolled back in their heads.
Clearly, there was no lack of intellectual capacity for this group, but there was a lack of available bandwidth for this topic and I had to optimize the small amount that I could get.
After several iterations and some informal trials (which largely consisted of me pitching the current iteration of my information risk presentation while walking with a doc in the hall on the way to the operating room), I came up with my single page approach. It consists of three components:
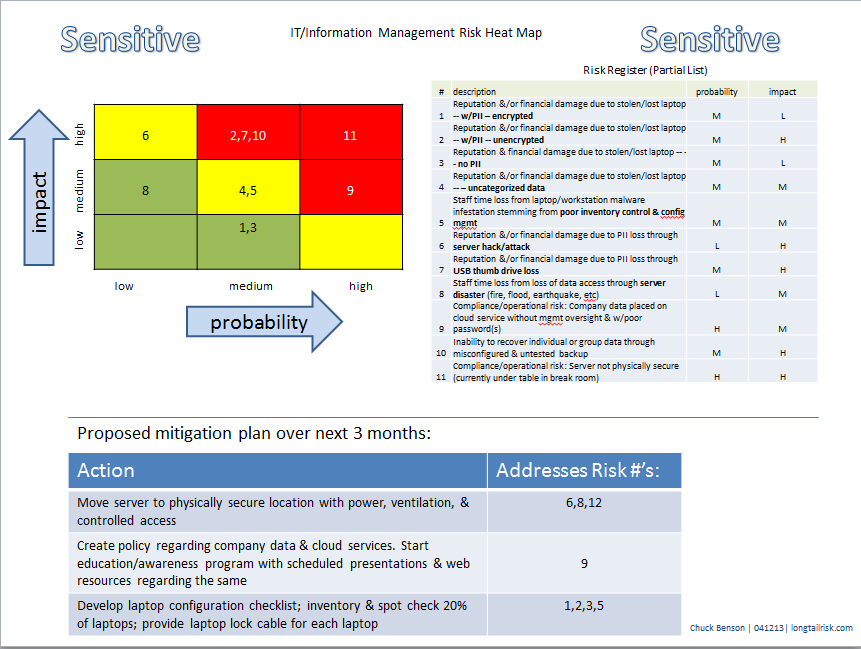
Communicate risk in a single page (click to enlarge)
I put the attention-getting colorful heat map in the upper left hand corner, the risk register in the upper right, and a proposed simple mitigation plan at the bottom of the page.
This ended up being pretty successful. I actually managed to engage them for 5 – 10 minutes (which is a relatively large amount of time for them) and get them thinking about information risk in their environment.
To communicate risk in a single page, I am choosing to leave information out. This can tend to go against our nature in wanting to be very detailed, comprehensive, and thorough in everything that we do. However, that level of detail will actually impede communication. And I need to communicate risk. By leaving information out, I actually increase the communication that occurs.
Also, notice in the Proposed Mitigation section, I am not proposing to solve everything in the register. I am proposing to solve things that are important and feasible in a given time frame (three months in this case).
In three, six, or nine months, we can come back with a new presentation that includes results from the proposed mitigation in this presentation.
Notice that I put “Sensitive” in a couple of places on the document to try to remind people that we don’t want to share our weak spots with the world.
If at some point, your company leadership or other stakeholders want more detail, that’s fine. If they ask for it, they are much more likely to be able and willing to consume it.
To communicate risk, start simple. If they want more, you’ll be ready by being able to use your working risk register as a source. I’ll be willing to be bet, though, that most will be happy with a single page.
Have you presented information risk to your constituents before? What techniques did you use? How did it go?
Climbing aboard the helicopter for a training flight one evening was probably the first time that I thought about the difference between probability and impact as components of risk. For whatever reason, I remember looking at the tail rotor gearbox that particular evening and thinking, “What if that fails? There aren’t a lot of options.”
Tail rotor failures in helicopters are not good. The tail rotor is what provides the counterbalance for the torque generated by the main rotor that generates all of the lift. It’s what keeps the fuselage of the helicopter from spinning in the opposite direction of the main rotor in flight. If the tail rotor fails in some way, not only are you no longer in controlled flight (because the fuselage wants to spin around in circles), but the emergency procedures (EP’s) are pretty drastic and probably won’t help much.

tail rotor gearbox
So I found myself thinking, “Why in the world would I (or anyone) climb on board when something so catastrophic could happen?” And then the answer hit me, “because it probably won’t fail.” That is, the impact of the event is very bad, but the probability of it happening is low. This particular possibility represented the extremes — very high impact and generally low probability.

nose gear
But there are possibilities in between also. For example, what if the nose gear gets stuck and won’t come back down when I want to land. While not desirable, it’s certainly not as bad as the tail rotor failing. I could come back and land/hover and keep the nose gear off the deck while someone comes out and tried to pull it down. Or they could put something underneath the nose of the helicopter (like a stack of wooden pallets) and set it down on that. While not a high likelihood of occurrence, a stuck nose gear happens more often than a tail rotor failure, so let’s call it a medium probability for the sake of argument.
While the impact of the stuck-nose-gear-event is much less than that of the tail rotor failure, the potential impact is not trivial because recovery from it requires extra people on the ground that are placed in harm’s way. So maybe this is a medium impact event.

multiple components/multiple systems
Similarly, what if the main gear box overheats or has other problems? Or other systems have abnormalities, problems or failures? What are the probabilities and impacts of each of these?
There are multiple pieces to the puzzle and each piece needs to be considered in terms of both impact and likelihood. Even as commercial airline passengers,
If we based our decision to fly purely on an analysis of the impact of an adverse event (crash), few people would ever fly.
We do board the plane, though, because we know or believe that the probability of that particular plane crashing is low. So, in making our decision to fly, we consider two components of risk: the probability of a mishap and the impact of a mishap.
We have the same kind of thing in managing risk for IT and Information Management services. We have many interconnected and complex systems and each has components with various probabilities of failure and resulting impacts from failure.
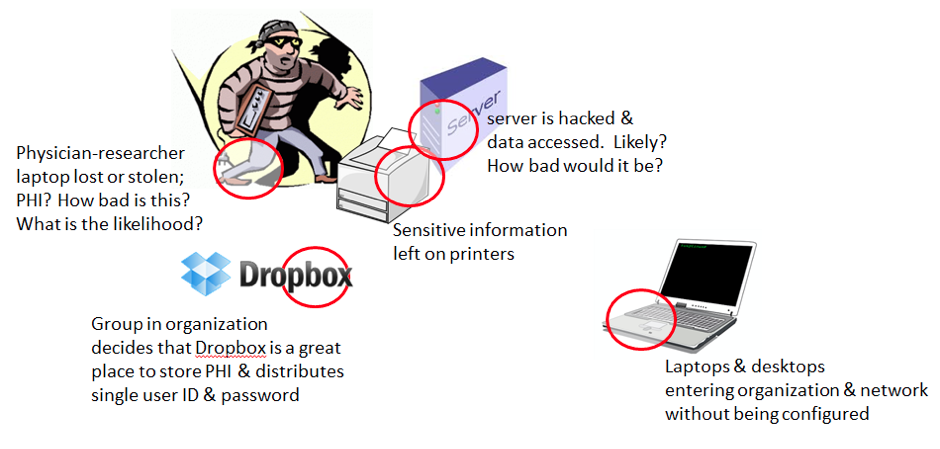
multiple components and multiple systems in IT & Information Management systems as well
What if I’m working in a healthcare environment and users store Protected Health Information (PHI) on a cloud service with a shared user name and password and PHI leaks out into the wild? This might have risk components of: Probability — High. Impact — Medium to High, depending on size of leak. What about laptop theft or loss containing PHI? Same for USB thumb drives. What is the probability? What is the impact? What about malware infestation of workstations on your network because of lack of configuration standards on BYOD devices? What is the likelihood? What is the impact?
It’s possible that our server or data center could be hit with an asteroid. The impact would be very high. Maybe there are multiple asteroids that hit our failover servers and redundant data centers also ! That would surely shut us down. But does that mean that we should divert our limited business funds to put our server in an underground bunker? Probably not — because the likelihood of server failure due to asteroid impact is very low.
As with flying, when we analyze risks in IT and Information Management operations, we have to dissect and review the events in terms of their respective impacts and probabilities. Only when we have these two components, impact vs probability, can we start to do meaningful analysis and planning.
What are events do you plan for that have Low Probabilities but High Impacts? What about High Probabilities but Low Impacts?
Visualization is a powerful tool for simple information risk analysis. The simple of act of placing risks in spacial relationship to each other allows a quick overview of essential elements of your risk profile. As importantly, it allows you to communicate that simple risk profile to others that aren’t as versed in information security, IT, and information management. A popular risk visualization tool is an information risk heat map.
A couple of posts ago, I talked about creating a simple risk register. In a nutshell, this is a list of things that can go wrong in the IT and information management part of your business with an estimate of how bad it would be and how likely you think it is to happen. An example might be as simple as, “business shutdown for greater than 3 days because no backup for critical data — medium probability, high impact” or “data inaccessibility because of failure of cloud services provider — medium probability, medium impact.”
As a reminder, keep your analysis simple for probability and impact of event. I suggest just Low, Medium, or High to start. As a small or medium-sized company, you probably don’t have a lot of data to drive estimates for probability, so just make your best educated estimate. For example, if I’ve got a server with a RAID 5 configuration, I think the chances of 2 disks failing simultaneously (resulting in data loss) is Low. Similarly, for impact, keep the analysis of impact pretty simple to start. For example, amount of time offline might be a guideline for you — maybe 4 hours or less offline is Low impact for you, 4 hours to 2 days is Medium, and greater than 2 days is High. How you define impact is a statement of your business’s “risk tolerance” and will vary from business to business. The main thing to remember is to not make it overly complicated.
The heat map is going to be a simple 3 x 3 grid with probability on one axis and impact on the other. The cells inside the grid will contain the actual risks.
In the original risk register example, there were four columns: risk description, probability, impact, and then a column for date added. To create the heat map, we’re going to add one more column to the far left simply called Risk #. This is just a number to identify the risk. It doesn’t indicate any sort of risk priority.
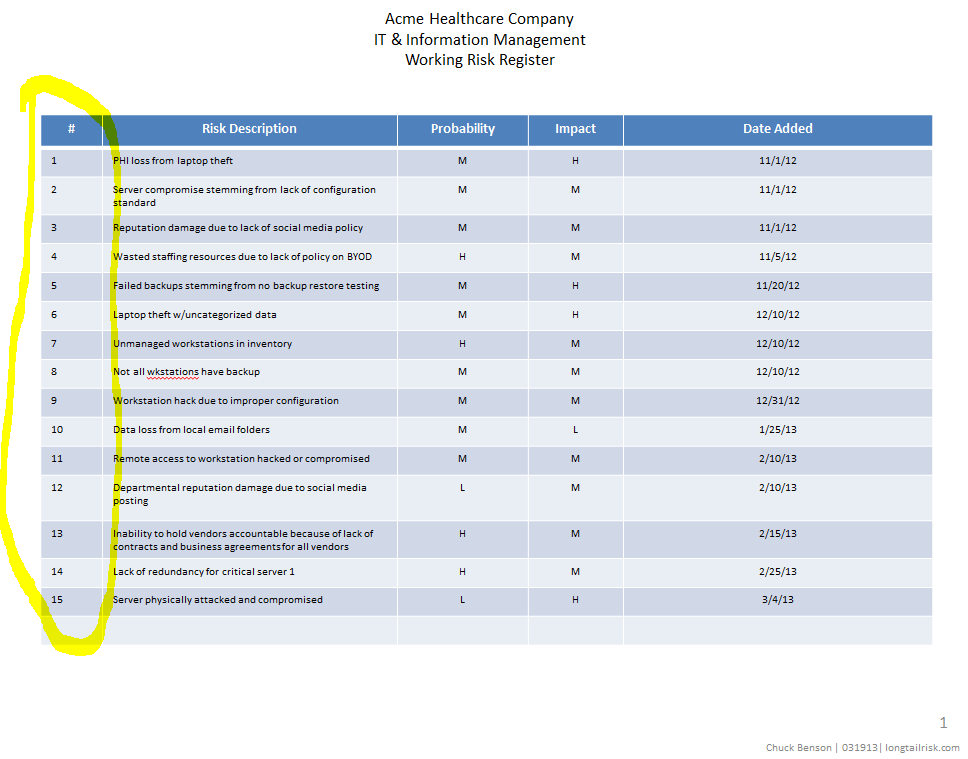
information risk register with numeric indices
Once you have the risk register that includes the Risk # column (which is just an index to the risk description and not a priority), start your heat map by creating a 3 x 3 grid with probability of the event happening on one axis and impact of the event of the other axis.
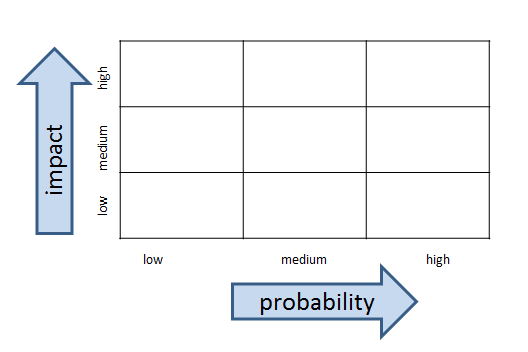
basic information risk management heat map grid
If you’d like add some color:

information risk management heat map grid with color
Finally, add the risk index #’s from your risk register
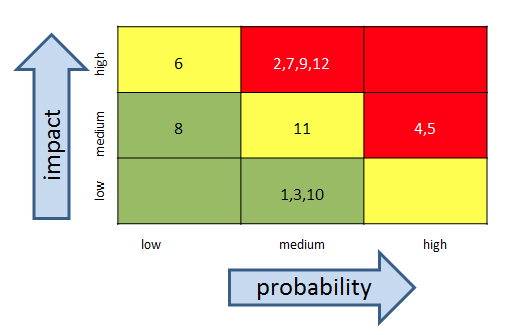
information risk management heat map grid with risk indices
Once people orient to axes on the heat map, their eyeballs generally go directly to the upper right hand corner of the heat map where the higher impact and probability events are. This is not a bad thing.
With your simple heat map, and without a lot of work, you now have some insight into your operation’s risk profile and are in a better position to make informed business decisions.
Have you created information risk registers or information risk heat maps before? What did you use for criteria for impact?
Starting an IT risk management program in the traditional sense appears daunting, and usually is, to a small or medium-sized business. This is one of the reasons that they often don’t get started. To make the insurmountable surmountable, start a simple risk register. If you haven’t already, start one today. Napkins, yellow legal pads, Moleskine notebooks, Evernote notes, etc all work to start.
Starting and developing a risk register will:
The simplest risk register will have three columns — a simple risk description, a likelihood of the event happening, and the impact of it happening. (Adding a fourth column that contains the date of when you added the risk can be helpful, but is not required).

Start with writing down the risks as soon as you think of them. If you haven’t done this before, several will probably pop into your head right off. The act of writing something down is deceptively powerful. It makes you articulate the problem and maybe revisit a couple of your assumptions about the problem. That said, don’t go nuts analyzing any particular risk when you start. Just get the core idea down, maybe something like, “PII loss resulting from laptop theft” or “reduced support effectiveness because of lack of BYOD policy.”
After you’ve got a dozen or so, take a break for now (you’ll add more later), and review the whole list. Make two columns next to this list. Label one column ‘probability’ and the other column ‘impact’. Next to each risk, write down what you think the likelihood of that event occurring — just High, Medium, or Low. Nothing fancier than that. Same thing with impact — how bad would it be if this event occurred? What’s the impact? Again, just High Medium or Low.
When you have a few minutes, you can structure this a little bit more by putting this in a table. I like using Powerpoint or Keynote over Excel/Numbers for this stage. By using Powerpoint’s cartoonish and colorful tables, I tend to stay oriented to the fact that I’ll be communicating these risks (or some of these risks) later on. If I use Excel for this, I tend to get overly analytical and detailed. It starts to become more of a math problem vs something that I will be communicating to others.
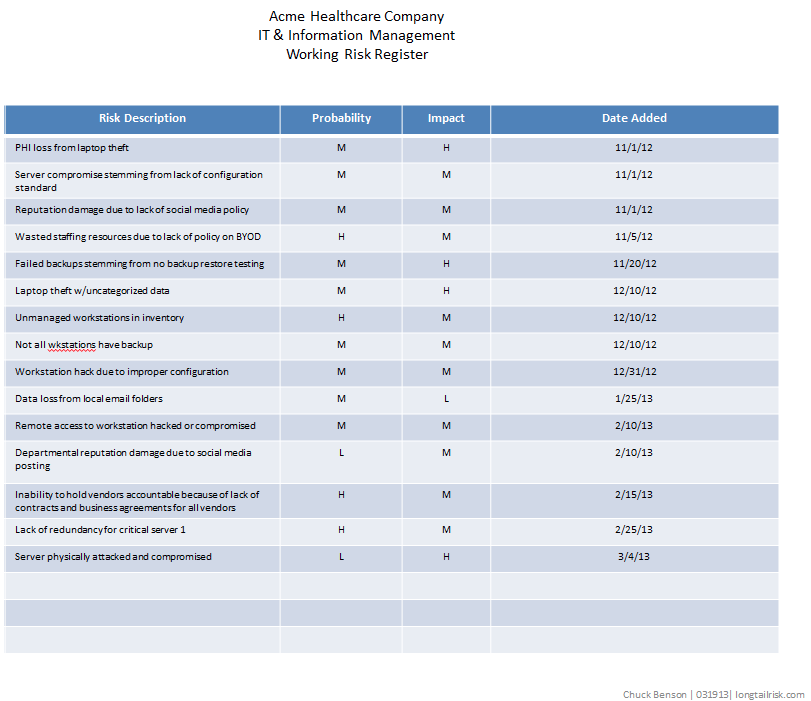
(click to enlarge)
Keep in mind, that it is very easy to over-design beyond the point that is useful to you right now. And you want it to be useful to you right now. At this point, you are creating a simple document that informs you in that brief moment of time that have to look at it. You don’t want a document that taxes you right now. It needs to give you a quick easily digestible and broad view of your risk picture. If the document gets too complicated or goes into too much detail, you increase the likelihood that you won’t pick it up again tomorrow or in a week or in a month.
In an upcoming post, we’ll create a simple visualization tool, called a heat map, that can be very helpful in providing a profile of your risk picture.
Do you currently use a risk register now? How did you create it? How do you maintain it?