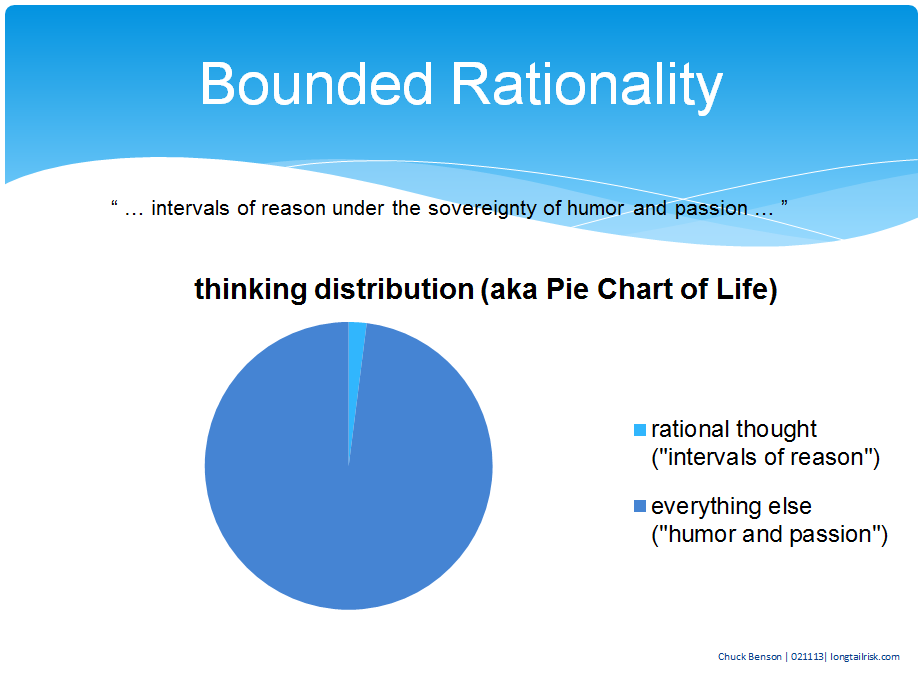
A shovel at a time
The Shodan data source can be a good way to begin to profile your organization’s exposure created by Industrial Control Systems (ICS) and Internet of Things (IoT) devices and systems. Public IP addresses have already been scanned for responses to known ports and services and those responses have been stored in a searchable web accessible database — no muss, no fuss. The challenge is that there is A LOT of data to go through and determining what’s useful and what’s not useful is nontrivial.
Data returned from Shodan queries are results from ‘banner grabs’ from systems and devices. ‘Banner grabs’ are responses from devices and systems that are usually in place to assist with installing and managing the device/system. Fortunately or unfortunately, these banners can contain a lot of information. These banners can be helpful for tech support, users, and operators for managing devices and systems. However, that same banner data that devices and systems reveal about themselves to good guys is also revealed to bad guys.
What are we looking for?
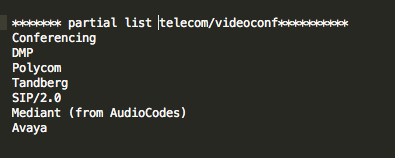
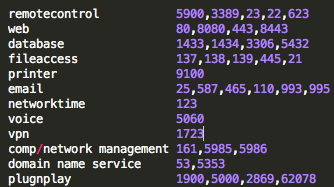
So what data are we looking for? What would be helpful in determining some of my exposure? There are some obvious things that I might want to know about my organization. For example, are there web cams reporting themselves on my organization’s public address space? Are there rogue routers with known vulnerabilities installed? Industrial control or ‘SCADA’ systems advertising themselves? Systems advertising file, data, or control access?
The Shodan site itself provides easy starting points for these by listing and ranking popular search terms in it’s Explore page. (Again, this data is available to both good guys and bad guys). However, there are so many new products and systems and associated protocols for Industrial Control Systems and Internet of Things that we don’t know what they all are. In fact, they are so numerous and growing that we can’t know what they all are.
So how do we know what to look for in the Shodan data about our own spaces?
Excavation
My initial approach to this problem is to do what I call excavating Shodan data. I aggregate as much of the Shodan data as I can about my organization’s public address space. Importantly, I also research the data of peer organizations and include that in the aggregate as well. The reason for this is that there probably are some devices and systems that show up in peer organizations that will eventually also show up in mine.
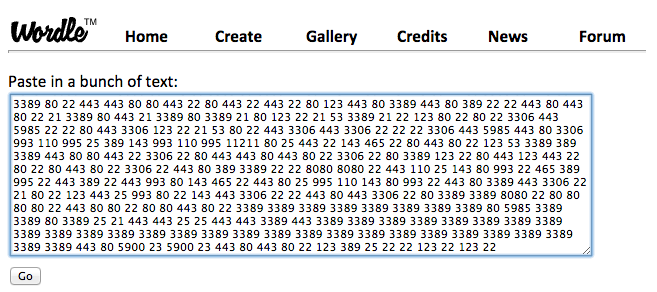
Next, using some techniques from online document search, I tokenize all of the banners. That is, I chop up all of the words or strings into single words or ‘tokens.’ This results in hundreds of thousands of tokens for my current data set (roughly 1.5 million tokens). The next step is to compute the frequency of each, then sort in descending order, and finally display some number of those discovered words/tokens. For example, I might say show me the 10 most frequently occurring tokens in my data set:

Top 10 most frequently occurring words/tokens — no big surprises — lots of web stuff
I’ll eyeball those and then write those to a stoplist so that they don’t occur in the next run. Then I’ll look at the next 10 most frequently occurring. After doing that a few times, I’ll dig deeper, taking bigger chunks, and ask for the 100 most frequently occurring. And then maybe the next 1000 most frequently occurring.
This is the excavation part, gradually skimming the most frequently occurring off the top to see what’s ‘underneath’. Some of the results are surprising.
‘Password’ frequency in top 0.02% of banner words
Just glancing at the top 10, not much is surprising — a lot of web header stuff. Taking a look at the top 100 most frequently occurring banner tokens, we see more web stuff, NetBIOS revealing itself, some days of the week and months, and other. We also see our first example of third party web interface software with Virata-EmWeb. (Third party web interface software is interesting because a vulnerability here can cross into multiple different types of devices and systems.) Slicing off another layer and going deeper by 100, we find the token ‘Password’ at approximately the 250th most frequently occurring point. Since I’m going through 1.5 million words (tokens), that means that ‘Password’ frequency is in the top 0.02% or so of all tokens. That’s sort of interesting.
But as I dig deeper, say the top 1500 or so, I start to see Lantronix, a networked device controller, showing up. I see another third party web interface, GoAhead-Webs. Blackboard often indicates Point-of-Sale devices such as card swipers on vending machines. So even looking at only the top 0.1% of the tokens, some interesting things are showing up.
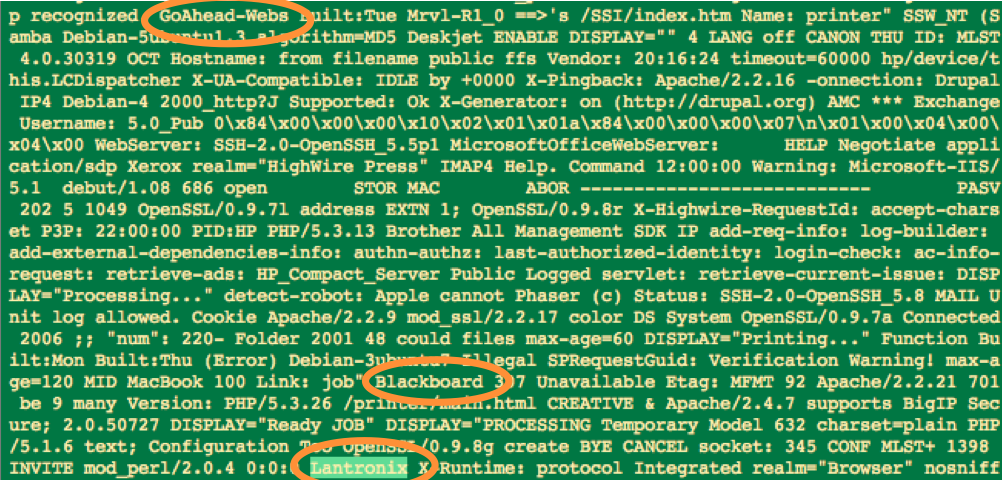
Digging deeper — Even in the top 0.1% of tokens, interesting things start to show up
New devices & systems showing up
But what about the newer, less frequently occurring, banner words (tokens) showing up in the list? Excavating like this can clearly get tedious, so what’s another approach for discovery of interesting, diagnostic, maybe slightly alarming words in banners on our networks? In a subsequent post, I’ll explain my next approach that I’ve named ‘cerealboxing’, based on an observation and concept of Steve Ocepek’s regarding our human tendency to automatically read, analyze, and/or ingest information in our environment, even if passively.