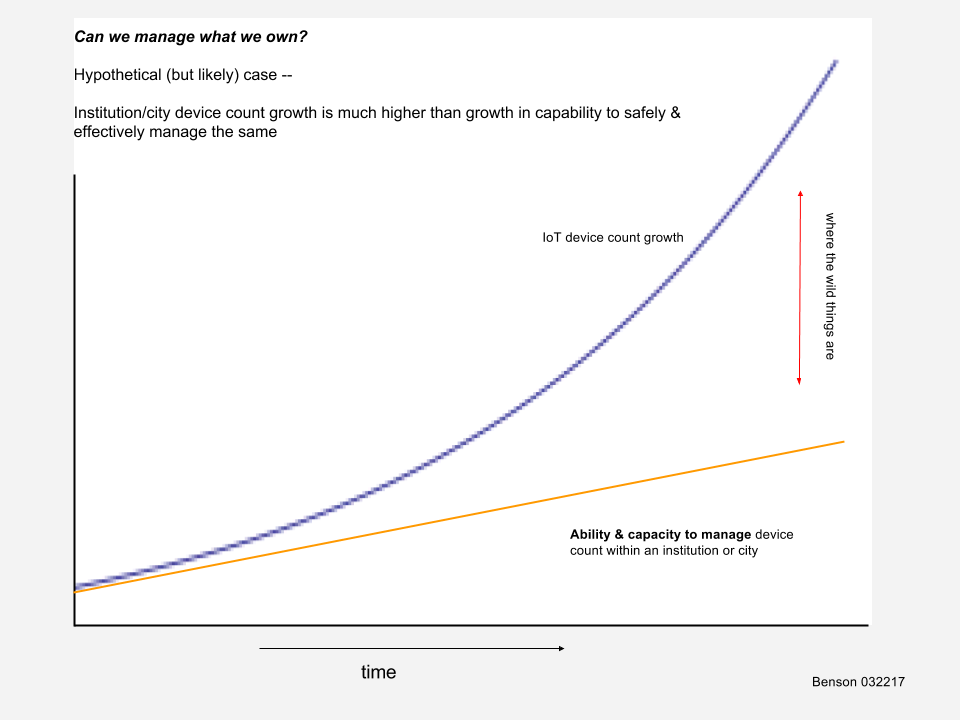
The rate of growth of IoT devices and systems is rapidly outpacing the ability of an institution or city to manage those same devices and systems. The tools, capacities, and skill sets in institutions and cities that are currently in place were built and staffed for different information systems and technologies — centralized mail servers, file sharing, business applications, network infrastructure support, and similar. Some of these systems still exist within the enterprise and still need robust, effective support while others have moved to the cloud. The important consideration is to not assume that toolsets developed for traditional enterprise implementations are appropriate or sufficient for IoT Systems implementations.

things are increasing faster than the ability to manage those things
Working from the outside in
Starting with the outer ring, the number of ‘things’ — the T in IoT — is rapidly growing within institutions and cities. From my perspective, an IoT ‘thing’ is a device that computes in some way, is networked, and interacts with its local environment in some way. Further, these systems may be acquired via non-traditional methods. For example, a city’s transportation department may seek and acquire a sensor, data aggregation, and analysis system for predictive maintenance for a particular roadway. This system might have been selected, procured, implemented, and subsequently managed independently of the organization’s traditional central IT organization & processes. Complex and high data producing systems are entering the institution/city from a variety of sources and with little formal vetting or analysis.
Can we even count them?
Because of the rapid growth of IoT devices and systems in concert with alternative entry points into the city/institution, even counting (enumerating) — these devices — which can compute with growing ability and are networked — is increasingly difficult. This lack of countability in itself is not so bad, it’s just a fact of life – the trouble comes when we base our management systems on the assumption that we can count, inventory, much less manage all of our devices.
What do we know about the devices?
Do we have documentation and clarity of support for the tens, hundreds, thousands (or more) of devices. What do they do? How are they configured? Have we set a standard for configuration? How do we know that that standard is being met? What services do we think should be running on the devices? Are those services indeed running on them? Are there more services than those required running? Are there processes for sampling and auditing those device services over the next 12 – 36 months? Or did we install them, or have them installed, and simply move onto the next thing?
We can borrow from the construction industry and ask for as-built documentation. What actually got installed? What are the documents that we have to work with to support this system? Drawings? IP addresses? Configuration documents for logins, passwords, open ports/services?
What is manageable?
If we are in the fortunate position to be able to actually count these computing/networked/sensing devices with reasonable accuracy and we know some (enough) things about the devices, then the next question is — do we have the resources — staffing, time, skill sets, opportunity cost, etc — to actually support the devices? Suddenly in smart cities, smart institutions, smart campuses, we’re installing things, endpoints, in the field that may require regular updating (yearly, monthly, …) — and this occurs between the customer network with its protocols/processes and the vendor system that is proposed. Not all (possibly substantial) device updating can be accomplished effectively remotely.
Another challenge is that often the organizations that are charged with staffing, installing, and supporting these deployed IoT devices, such as smart energy meters or environmental monitoring systems, are more accustomed to supporting machines that last for years or decades. Such facilities management organizations have naturally built their planning, repair, and preventative maintenance cycles around longer periods. For example, a centrifugal fan in a building might have a projected lifespan of approximately 25 years, soft start electric motors 25 years, and variable air volume (VAV) boxes with expectancies of 25 years.
Similarly, central IT organizations generally are not accustomed to running out into the field with trucks and ladders to support 100’s, 1000’s, or more of computing, networked devices in a city or institution. So the question of who’s going to do the actual support work in the field is not clear in terms of capacity, skill sets, and costs.
Actually managing the things
So, if we have all of the above — and that subset gets smaller and smaller — have the decisions been made and priorities established to actually manage the devices? That is, to prioritize, risk manage, and develop process to manage the devices in practice? There’s a good chance that manageable things won’t actually be managed due to lack of knowledge of owned things, competing priorities, and other.
On not managing the things
It is my opinion that we will not be able to manage all of the ‘things’ in the manner that we have historically managed networked, computing things. While that’s a change, that’s not all bad either. However we do have to realize, acknowledge, and adjust for the fact that we’re not managing all of these things like we thought we could. Thinking we’re managing something we’re not is the biggest risk.
We’re moving into a world of potentially greater benefit to the populace via technology and information systems. However, we will have to do the hard work of being thoughtful about it across multiple populations and realize that we’re bringing in new risks with some known — and unknown — consequences.