
 In 2010, Steve Ocepek did a presentation at DefCon where he introduced an idea that he called ‘cerealboxing’. In it, he made a distinction between visibility and visualization. He suggested that visualization uses more of our ability to reason and visibility is more peripheral and taps into our human cognition. He references Spivey and Dale in their paper Continuous Dynamics in Real-Time Cognition in saying:
In 2010, Steve Ocepek did a presentation at DefCon where he introduced an idea that he called ‘cerealboxing’. In it, he made a distinction between visibility and visualization. He suggested that visualization uses more of our ability to reason and visibility is more peripheral and taps into our human cognition. He references Spivey and Dale in their paper Continuous Dynamics in Real-Time Cognition in saying:
“Real-time cognition is best described not as a sequence of logical operations performed on discrete symbols but as a continuously changing pattern of neuronal activity.”
Thinking on the back burner
Steve’s work involved building an Arduino-device that provides an indication of the source country of spawned web sessions while doing normal web browsing. The idea was that as you do your typical browsing work, the device, via numbers and colors of illuminated LEDs would give an indication of how many web sessions were spawned on any particular page and where those sessions sourced from. I built the device myself, ran it, and it was enlightening (no pun intended).
Using Steve’s device, while focused on something else — my web browsing, I had an indication out of the corner of my eye that I processed somewhat separately from my core task of browsing. Without even trying or ‘thinking’, I was aware when a page lit up with many LED’s and many colors (indicating many sessions from many different countries). I also became aware when I was seeing many web pages, regardless of my activity, that came from Brazil, for example.
Cerealbox
Steve named this secondary activity ‘cerealboxing’ as when you mindlessly read a cereal box at breakfast. From one of his presentation slides:
- Name came from our tendency to read/interpret anything in front of us
- Kind of a “background” technology, something that we see peripherally
- Pattern detection lets us see variances without digging too deep
- Just enough info to let us know when it’s time to dig deeper
Back to excavating Shodan data
As I mentioned in my last post, Shodan data offers a great way to characterize some of the risk on your networks. The challenge is that there is a lot of data.
One of the things that I want to know is what kinds of devices are showing up on my networks? What are some indicators? What words from ‘banner grabs’ indicate web cams, Industrial Control Systems, research systems, environmental control systems, biometrics systems, and others on my networks? I started with millions of tokens. How could I possibly find out interesting or relevant ‘tokens’ or key words in all of these?
To approach this, I borrowed the cerealboxing idea and wrote a script that continuously displays this data on a window (or two) on my computer. And then just let it run while I’m doing other things. It may sound odd, but I found myself occasionally glancing over and catching an interesting word or token that I probably would not have seen otherwise.

unordered tokens
So, in a nutshell, I approached it this way:
- tokenize all of the banners in the study
- I studied banners from my organization as well as peer organizations
- do some token reduction with stoplists & regular expressions, eg 1 & 2 character tokens, known printers, frequent network banner tokens like ‘HTTP’, days of the week, months, info on SSH variants, control characters that made the output look weird, etc
- scroll a running list of these in the background or on a separate machine/screen
I also experimented with sorting by length of the tokens to see if that was more readable:

sorted by order — this section showing tokens (words) of 5 characters in length
In the course of doing this, I update a list of related tokens. For example, some tokens related to networked cameras:

And some related to audio and videoconferencing:
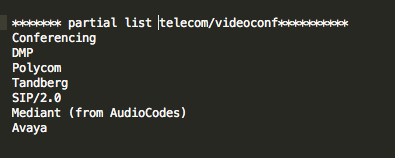
This evolving list of tokens will help me identify related device and system types on my networks as I periodically update the sample.
This is a fair amount of work to get this data, but once the process is identified and scripts written, it’s not so bad. Besides, with over 50 billion networked computing devices online in the next five years, what are you gonna do?