
Internet2 has launched a national Task Force to study risk management needs around IoT Systems in Higher Education and research institutions. The Task Force is composed of Higher Education and research IT and Information Management leaders across the country and will explore the areas of IoT Systems selection, procurement, implementation, and management. At the end of 12 months, the IoT Systems Risk Management Task Force will deliver a set of recommendations for 3 – 5 areas of further in-depth work. (And in the interest of full disclosure, I am Chairing the IoT Systems Risk Management Task Force.)
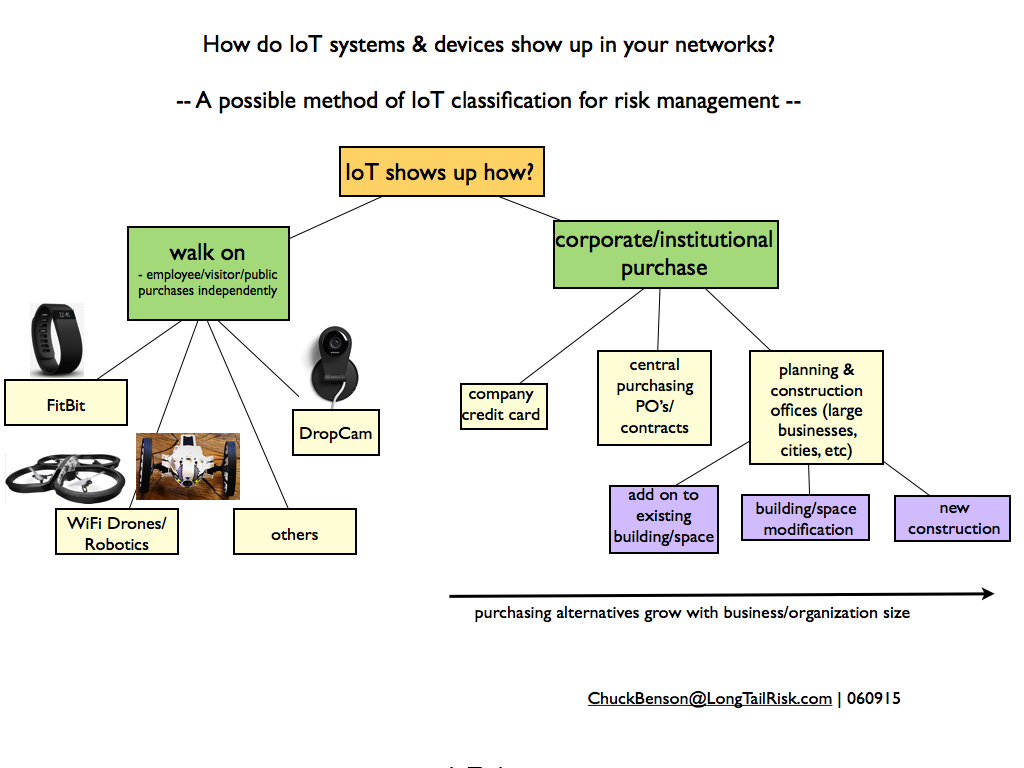
Internet of Things Systems or IoT Systems offer great potential value to higher education, research, government, and corporate institutions. From energy management, to research automation systems, to systems that enhance student, faculty, staff, and public safety, to academic learning systems, IoT Systems offer great promise. However, these systems need to be implemented thoughtfully and thoroughly or the investment value won’t be realized. Further, because of the distributed computing and networking capabilities of IoT devices, poor IoT Systems implementations can even make things worse for institutions, corporations, or governments.
Internet2 Chief Innovation Office
 The mission of the Internet 2 Chief Innovation Office, led by Florence Hudson, is to work with Internet2 members to define and develop new innovations around the Internet. The Innovation Program has three core working groups —
The mission of the Internet 2 Chief Innovation Office, led by Florence Hudson, is to work with Internet2 members to define and develop new innovations around the Internet. The Innovation Program has three core working groups —
Internet2’s core offerings are its 100 gbps network and their NET+ services. Their membership includes 300 Higher Education institutions and over 150 industry, lab, and national agency organizations.
Many IoT systems risk topics
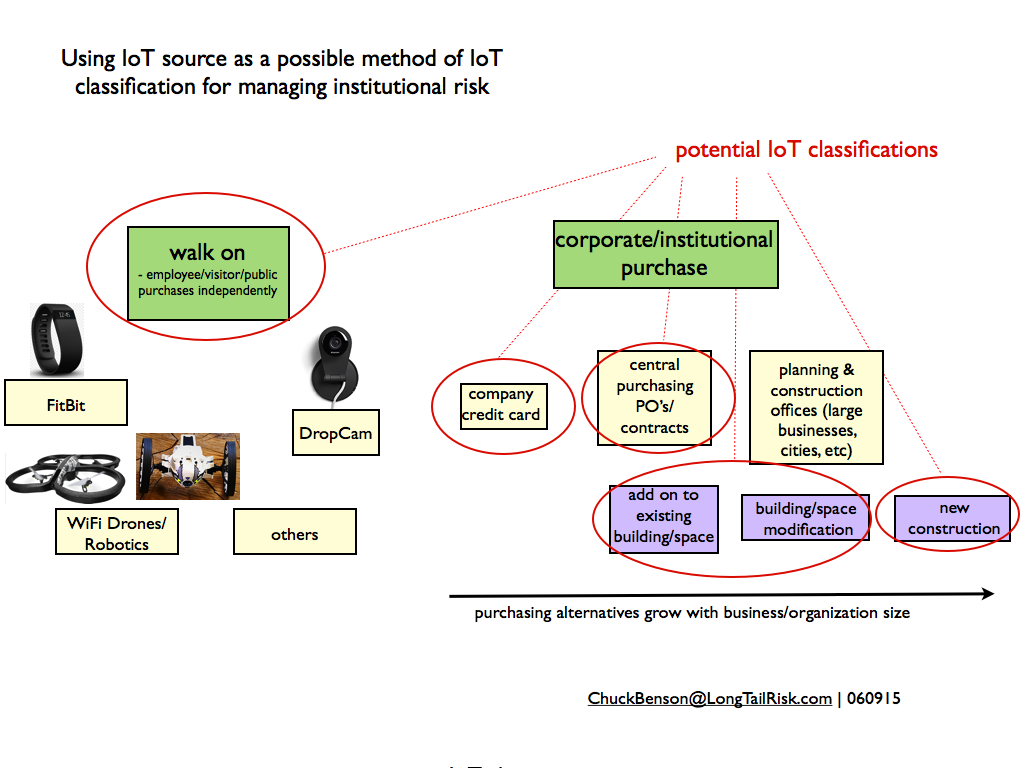
Examples of topics that the Task Force will cover include IoT systems vendor management issues, network segmentation strategies and approaches, cost estimating tools and approaches for IoT systems, potential tool development and/or partnering with organizations that perform Internet-wide scanning for IoT-related systems, and the organizational and cultural issues encountered in transitioning to a data-centric organization.
IoT systems vendor management approaches
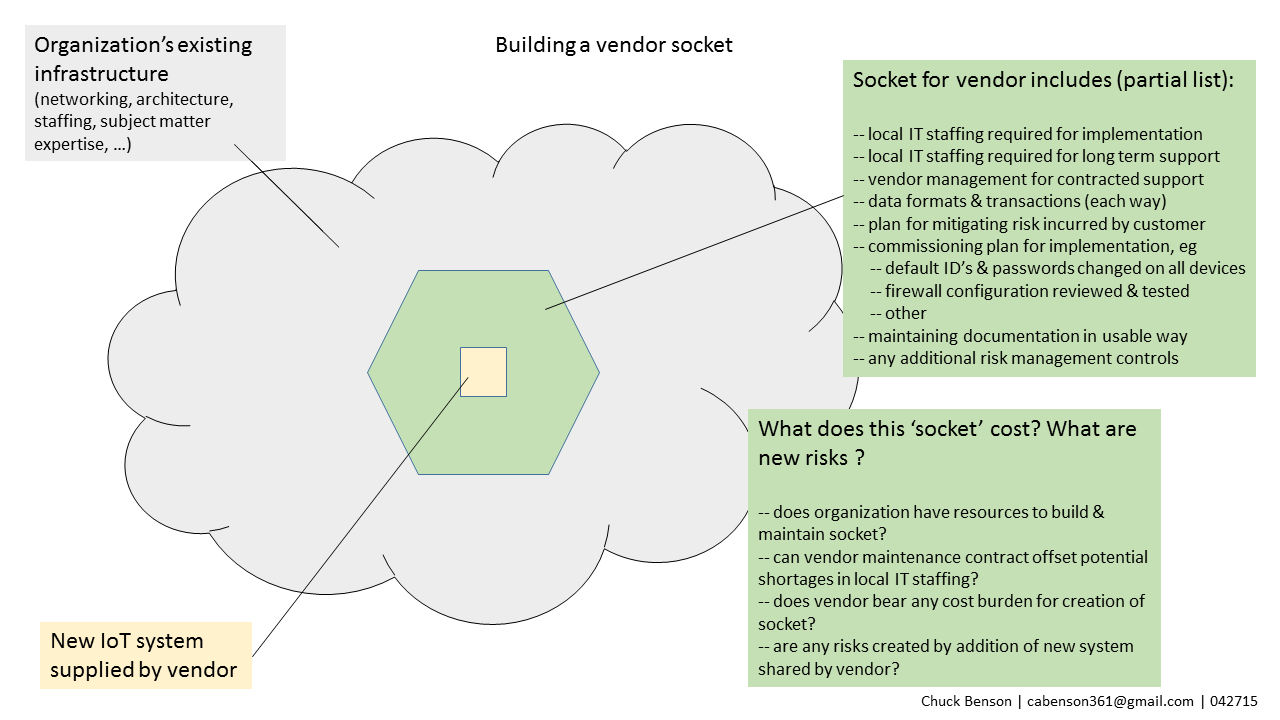
Organizations and institutions need to raise the bar with IoT systems vendors regarding what constitutes a successfully delivered product or service. For example, has the vendor delivered documentation showing the final installation architecture, have default logins & passwords been change on all devices (how is this demonstrated), have all unnecessary services been deactivated on all devices and systems and how is this demonstrated?
Development of common ‘backends’ for IoT systems
Current IoT systems (to include utility distribution, building automation systems, many others) vendor approaches require that institutions invest in separate and proprietary ‘backend’ architectures consisting of application servers, databases, etc for each different vendor. This is an approach that does not lend itself to manageability, extensibility, or scalability. In this space, perhaps newer container and container management technologies offer solutions as well as other possibilities.
 Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems
Development of network segmentation/micro-segmentation strategies and approaches for IoT Systems
Network segmentation seems to offer great promise for mitigating risk around IoT Systems implementations. However, without appropriate guidance for IoT network segmentation implementation and operation, institutions can end up with a full portfolio of poorly managed network segments. Exploration and development of institutional network segmentation best practices can serve to lower an organization’s risk profile.
Development of cost estimating tools and approaches for IoT Systems
There is little in the way of precedent for cost models for the rapidly evolving IoT systems space and, as such, planning for IoT Systems and trying to estimate Total Cost of Ownership is difficult and nuanced. Exploration of and development of IoT Systems cost models can be of real value to institutions making planning and resourcing decisions.
Development of risk language & risk categories around IoT systems
Currently it is difficult to discuss new risk brought on by IoT systems with enterprise risk managers because IoT systems themselves are difficult to describe and discuss. Development and socializing IoT risk language, that incorporates existing familiar institutional risk language, would enhance the ability to discuss IoT systems risk at the enterprise level. This Task Force will explore this nuanced space as well.
Analysis tool development and partnering
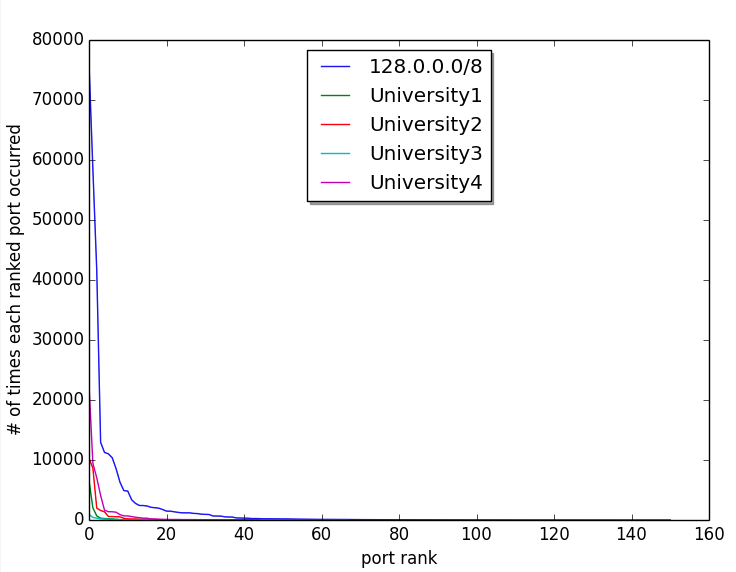
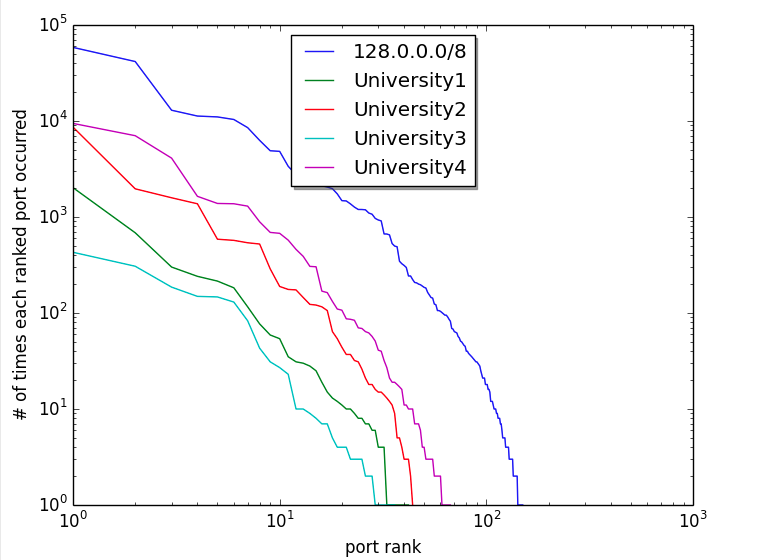
The Task Force will explore tool development and/or partnerships with organizations that scan the Internet for industrial control systems and IoT systems and publish these results online. Exploring internal tool development of the same is also a possibility. Development of benchmarks and baselines of Internet-scanning results across different industries and market sectors will also be considered.
Organizational cultural barriers to successful implementation of IoT Systems
Changing from a traditional organization to a data centric organization is a non-trivial transition and not addressing these issues can be a barrier to successful implementations of IoT Systems in institutions, organizations, and cities. The Task Force will study this important space as well.
Early Task Force work will also include identifying and enumerating other independent and overlapping risk areas (operational, cyber, cultural, and others). Over the year, Task Force members will participate in phone conferences, listen to subject matter expert presentations, and identify, discuss, and prioritize IoT Systems issues. Finally, recommendations will be made for further focused work on the highest priority areas. If you have questions, comments, further interest, please contact me ChuckBenson@longtailrisk.com or the Internet2 Chief Innovation Office at CINO@internet2.edu.
[IoT image above: By Wilgengebroed on Flickr – https://www.flickr.com/photos/wilgengebroed/8249565455/, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=32745541]












{kind=link}